









18 mins ago
6,464
Source: Denglian Community
In the first article in our Rollup 2.0 series, we discussed Based Rollup, where based on sorting is one of the most decentralized ways. It is also an Ethereum-compatible method for managing rollups. By handing over the transaction sorting task to Ethereum’s Layer 1, Based Rollup takes advantage of L1’s decentralization, simplicity and activity, among other advantages.
In today's article, we explore the next evolution of rollup: Booster rollup. Booster rollup not only builds on the basis of Based Rollup, but also promotes the composability boundary of Ethereum. But how exactly do we extend this composability?
What are the current problems in the L2 field?To ensure that the L2 network is functioning as expected, additional checks are usually required. However, the main settlement and execution process still occurs directly at L1. This means that while L2 extends off-chain EVM execution, it also adds additional complexity. Although this extra logic is not ideal, the ultimate goal is to standardize operations and rely entirely on standard EVMs.
Standardization is crucial to achieve a smooth transaction exchange between different L2s. To achieve this, a new type of transaction may be needed—a transaction that can operate across multiple chains. In this system, a transaction can create multiple smaller subtransactions. Each sub-transaction will include detailed information such as source chain ID, destination chain ID, input data (such as caller, address and call data), and result output from destination chain.
These transaction data plays two important roles:
It acts as input to the source chain, allowing participants to view the output without directly involving the destination chain.
It is used on the destination chain to confirm that the given input produces the expected output.
This method allows each chain to independently verify its own transaction while following the shared standard transaction format and input. Therefore, block verification is kept simple, using the familiar L1 verification contract to ensure the validity of the block.
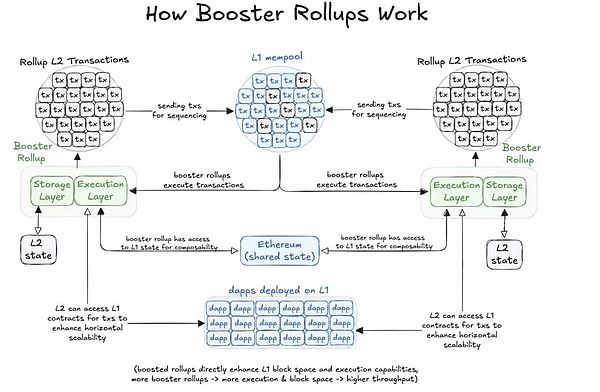
What are the differences between Booster rollup?Booster rollup treats transaction processing as doing on L1, with the ability to access L1 state, but has independent storage that extends both execution and storage to L2. Each L2 expands the block space of L1, decentralizing transaction processing and data storage.
Imagine that you only need to deploy a decentralized application (dapp) once and it will automatically scale to all Layer 2 (L2) networks. If you need more block space, just add more booster rollsup, and no other configuration is required. In other words, developers have no additional workload, no redeployment costs, and no additional complexity.
In layman's terms, booster rollup is like adding an extra CPU or SSD to your laptop: they improve performance, make applications run more efficiently, and scale easily.
For technical readers, booster rollup can also be described as "distributes the execution and storage of transactions in multiple shards."
How does Booster rollup work?Any rollup, whether optimistic or ZK, can adopt the booster function. However, not all rollups need to be fully improved, as some may benefit from L2-specific optimizations.
The best scenario for improvement is Based Rollup, if the goal is to implement local Ethereum expansion. By allowing L1 validators to propose blocks for the entire elevated network, you are actually expanding Ethereum seamlessly.
Booster Rollup also solves the fragmentation problem in the current rollup ecosystem. By leveraging sort-based, they maintain the benefits of L1 sorting while introducing atomic cross-rollup transactions within the augmented network. This setup allows the implementation of the initially envisioned Ethereum extension – integrated and broad, providing a unified solution to meet the growth challenges of Ethereum.
Description of booster rollup architecture
Because booster rollup essentially supports synchronous composability, this rollup model eliminates the hassle of dealing with fragmentation or switching between L2s. All preferred dapps will be available on every L2, providing a seamless Ethereum experience.
Booster Rollup allows developers to scale their dapps without having to do multiple redeploys on L2. Just deploy the dapp on L1, which automatically scales to all existing and future enhanced L2, simplifying the overall development and deployment process.
What teams are building booster rollup?One of the few teams currently building booster rollup is Taiko Gwyneth, which is also a composable based Rollup synchronized with Ethereum. Gwyneth uses the basis of Ethereum, and the transaction sorting is by L1. Processed by a validator, the block is assembled by a compatible L1 builder.
Gwyneth embodies synchronous composability by enhancing and extending L1 capabilities. By local sorting, it allows for smooth integration between rollup and L1 state. As the demand for block space increases, deploying additional booster rollups becomes simple, just like upgrading your laptop with more CPU or SSDs to enhance computing power and expand your application. Gwyneth envisions a seamless integration of Ethereum without fragmentation.
Gwyneth introduces a pre-confirmation mechanism where L1 validators can commit to L2 status in advance, provide users with fast transaction confirmation and ensure that congestion and contention fees are distributed fairly among the base layer participants. . This innovation continues to drive after Taiko testnet pioneered based on pre-confirmation transactions.
From the beginning, Gwyneth aims to be final. Powered by Raiko, Taiko’s internal multi-certifier, aims to achieve synchronous composability. Currently, trusted execution environments (TEEs) are the minimum guarantee for execution, but are expected to utilize optimized zero-knowledge virtual machines (zkVMs), such as SP1, Risc0, and possibly many other devices in the future.
Booster rollup MeaningBooster rollup Transparently enhances scalability, like adding servers to a farm. This design allows applications to seamlessly utilize additional resources, ensuring developers can scale their solutions without the need for additional steps such as deploying complex L2 infrastructure.
They solve the fragmentation problem by providing a unified experience between L1 and L2. With smart contracts sharing the same address, users can enjoy consistency and simplicity whether they interact with L1 or L2 environments.
They solve the problem of deployment inefficiency, allowing developers to deploy only once on L1, making dapp support multiple rollups by default, and updates are managed by the center. Users enjoy a single address between networks, whether using EOA or smart wallets, making it easier to seamlessly trade between L1 and L2.
They solve the challenges faced by rollup operators, convince developers to deploy on their networks because dapps are automatically available. This concept is superimposed, and can combine booster with Based Rollup to achieve significant expansion. Not all L2s need to be booster rollups, allowing for the existence of hybrid networks.
They solve sovereignty and security issues by eliminating the need for specific packaging contracts, as smart contracts work the same way on L1 and L2, keeping developerscontrol. The security is enhanced by security for each dapp application rather than relying on bridges or specific implementations, thus solving the problem of single point of failure.
About Booster Rollups LimitationsTo ensure L2 mirrors L1, contract deployment should be limited to L1 only, ensuring unified access between L2. This is not a major limitation, because smart contracts can still behave differently through data-driven methods, such as storing contract addresses in storage, which may vary between different chains.
Although L1 holds shared data, this does not directly increase scalability, which is a challenge inherent in scalable systems. Developers must optimize to minimize this impact. Similar to traditional software, not all dapps can make full use of parallel processing. However, these dapps still benefit from interoperability; although they run on separate L2s, they are still universally accessible.
Booster Rollups are essentially an extension of the L1 chain, but have unique transaction execution and storage. To explain Booster Rollup transactions, L1 and L2 nodes must run synchronously. However, one approach might involve running L1 and L2 simultaneously on the same node, switching between shared L1 and L2 specific storage during transaction execution.
ConclusionBooster Rollups provides transformative solutions to Ethereum’s scalability challenges in improving transaction throughput and storage efficiency through seamless integration of L1. They solve problems such as decentralization and deployment inefficiency, allowing developers to easily scale dapps on multiple L2s while maintaining security and sovereignty. By simplifying scalability and facilitating interoperability, Booster Rollups paves the way for a more coherent and user-friendly Ethereum ecosystem.
In our next series, we will dive into the fascinating world of native Rollups and Gigagas Rollups, and explore how these technologies can further revolutionize the scaling landscape of Ethereum.
