









19 mins ago
7,167
Author: Su Yang, Hao Boyang; Source: Tencent Technology
As the "shovel seller" in the AI era, Huang Renxun and his Nvidia always believe that computing power will never sleep. In his GTC speech, Huang Renxun said that reasoning has increased the demand for computing power by 100 times
At today's GTC conference, Huang Renxun took out a brand new Blackwell Ultra GPU, as well as the server SKUs derived from reasoning and Agents, as well as the RTX family bucket based on the Blackwell architecture. All of this is related to computing power, but what is more important is how to consume the continuous computing power reasonably and effectively.
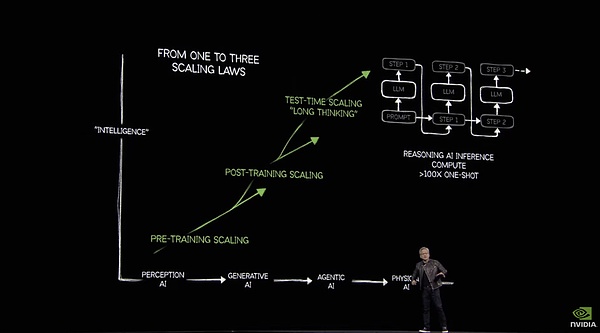
In Huang Renxun's eyes, computing power is needed to lead to AGI, embodied intelligent robots need computing power, and building Omniverse and world models requires a steady stream of computing power. As for how much computing power is needed for humans to build a virtual "parallel universe", Nvidia gave an answer - 100 times the past.
In order to support his own point of view, Huang Renxun posted a set of data on the GTC site - in 2024, the top four cloud factories in the United States purchased a total of 1.3 million Hopper architecture chips, and by 2025, this data soared to 3.6 million Blackwell GPUs.
The following are some core points of the Nvidia GTC 2025 conference compiled by Tencent Technology:
Blackwell Family Bucket is launched1) The annual "nuclear bomb" Blackwell Ultra is squeezing toothpasteNvidia GTC released the Blackwell architecture last year and launched the GB200 chip. This year's official name has been fine-tuned. It is not called the GB300 rumored before, but it is called Blakwell Ultra.
But from the hardware point of view, it was replaced with new HBM memory based on last year. In a word, Blackwell Ultra= Blackwell large memory version.
Blackwell Ultra consists of two TSMC N4P (5nm) processes, Blackwell architecture chip+Grace CPU is packaged and matched with more advanced 12-layer stacked HBM3e memory, the video memory is increased to 288GB, and supports the fifth generation NVLink like the previous generation, which can achieve 1.8TB/s of inter-chip interconnect bandwidth.
NVLink performance parameters
Based on storage upgrade, the FP4 accuracy computing power of Blackwell GPU can reach 15 PetaFLOPS, and the inference speed based on the Attention Acceleration mechanism is 2.5 times higher than that of Hopper architecture chips.
2) Blackwell Ultra NVL72: Special Cabinet for AI InferenceBlackwell Ultra NVL72 Official Picture
NVL72 Official Picture
NVL72 Cabinets This year, NVL72 also launched a similar product, Blackwell Ultra NVL72 Cabinet, consisting of 18 computing trays, each computing tray contains 4 Blackwell Ultra GPUs + 2 Grace CPUs, a total of 72 Blackwell Ultra GPUs + 36 Grace CPU, video memory reaches 20TB, total bandwidth of 576TB/s, plus 9 NVLink switch trays (18 NVLink switch chips), and NVLink bandwidth between nodes is 130TB/s.
The cabinet has built-in 72 CX-8 network cards, providing 14.4TB/s bandwidth. Quantum-X800 InfiniBand and Spectrum-X 800G Ethernet cards can reduce latency and jitter and support large-scale AI clusters. In addition, the rack integrates 18 BlueField-3 DPUs for enhanced multi-tenant networking, security and data acceleration.
Nvidia said that this product is specially customized "for the era of AI reasoning". The application scenarios include reasoning AI, Agent and physical AI (data simulation synthesis for robotics and intelligent driving training). Compared with the previous generation product GB200 NVL72, the AI performance of the previous generation product GB200 NVL72 is 1.5 times higher than that of the Hopper architecture.DGX cabinet products can provide data centers with a 50-fold increase in revenue.
According to the information provided by the official, the reasoning of the 671 billion parameter DeepSeek-R1 can achieve 100 tokens per second based on the H100 product, while the Blackwell Ultra NVL72 solution can achieve 1000 tokens per second.
Convert to time. For the same reasoning task, the H100 needs to run for 1.5 minutes, and the Blackwell Ultra NVL72 can be completed in 15 seconds.
Blackwell Ultra NVL72 and GB200 NVL72 hardware parameters
According to the information provided by NVIDIA, Blackwell NVL72 related products are expected to be launched in the second half of 2025. Customers include server manufacturers, cloud factories, and computing power rental service providers:
Server manufacturers
15 manufacturers including Cisco/Dell/HPE/Lenovo/Supermicro
Cloud factory
Mainstream platforms such as AWS/Google Cloud/Azure/Oracle Cloud
Computer power rental service provider
CoreWeave/Lambda/Yotta, etc.
3) Preview the real "nuclear bomb" GPU in advance Rubin chipsAccording to Nvidia's roadmap, GTC2025's home court is Blackwell Ultra.
However, Huang Renxun also used this venue to preview the next generation of Rubin architecture based on the Rubin architecture and the stronger cabinet VeraRubin NVL144—72 Vera CPUs + 144 Rubin GPUs, using a 288GB video memory HBM4 chip, a video memory bandwidth of 13TB/s, and is paired with the sixth-generation NVLink and CX9 network cards.
How strong is this product? The inference computing power of FP4 accuracy reaches 3.6ExaFLOPS, and the training computing power of FP8 accuracy also reaches 1.2ExaFlOPS, and the performance is 3.3 times that of Blackwell Ultra NVL72.
If you think it's not enough, it doesn't matter. There are stronger Rubin Ultra NVL576 cabinets in 2027. The FP4 accuracy inference and FP8 accuracy training computing power are 15ExaFLOPS and 5ExaFLOPS respectively, 14 times that of Blackwell Ultra NVL72.
Rubin Ultra NVL144 and Rubin Ultra NVL576 parameters provided by NVIDIA
4) Blackwell Ultra version of DGX Super POD "supercomputer factory"For customers who cannot meet the needs at this stage and do not need to build a super-large AI cluster, NVIDIA's solution is based on Blackwell Ultra, plug-and-play DGX Super POD AI supercomputer factory.
As a plug-and-play AI supercomputer factory, DGX Super POD is mainly aimed at AI scenarios such as generative AI, AI Agent and physical simulation, covering the full process computing power expansion requirements from pre-training and post-training to production environments. Equinix, as the first service provider, provides liquid-cooled/air-cooled infrastructure support.
DGX SuperPod built by Blackwell Ultra
DGX Super POD customized based on Blackwell Ultra is divided into two versions:
DGX SuperPOD with built-in DGX GB300 (Grace CPU × 1 + Blackwell Ultra GPU × 2), a total of 288 Grace CPUs + 576 Blackwell Ultra GPUs, providing 300TB of fast memory, and the computing power is 11.5ExaFLOPS with built-in DGX B300. This version does not contain Grace CPU chips, has further expansion space, and uses an air-cooled system. The main application scenarios are ordinary enterprise-level data centers
5) DGX Spark and DGX StationIn January this year, Nvidia showed off a conceptual AI PC product priced at CES - Project DIGITS. Now it has the official name DGX Spark. In terms of product parameters, it is equipped with a GB10 chip and FP4 accuracy, and can reach 1 PetaFlops with built-in 128GB LPDDR5X memory, CX-7 network card, 4TB NVMe storage, and runs DGX customized based on Linux. OS operating system supports frameworks such as Pytorch and is pre-installed with some basic AI software development tools provided by Nvidia, which can run a 200 billion parameter model. The size of the whole machine is similar to the size of the Mac mini. The two DGX Sparks are interconnected and can also run a model with more than 400 billion parameters.
Although we say it is an AI PC, it is still in the category of supercomputing in essence, so it is placed in the DGX product series, not in consumer-grade products such as RTX.
However, some people complain about this product, the promotional performance of FP4 is low, and when converted to FP16 accuracy, it can only be compared with RTX 5070 or even the 250 USD Arc B580 is benchmarked, so it has extremely low cost performance.
DGX Spark computer and DGX Station workstation
In addition to the official name DGX SPark, Nvidia also launched an AI workstation based on Blackwell Ultra. This workstation has a built-in Grace CPU and a Blackwell Ultra GPU, paired with 784GB of unified memory and CX-8 network card, providing 20 PetaFlops AI computing power (officially unmarked, theoretically FP4 accuracy).
6) RTX swept through AI PCs and squeezed into the data center. The previous introduction is SKUs based on Grace CPU and Blackwell Ultra GPU, and they are both enterprise-level products. Considering the wonderful use of products like RTX 4090 in AI reasoning, Nvidia's GTC has further strengthened the integration of Blackwell and RTX series, and launched a large wave of AI PC-related GPUs with built-in GDDR7 memory, covering notebooks, desktops and even data centers and other scenarios.Desktop GPU: including RTX PRO 6000 Blackwell Workstation Edition, RTX PRO 6000 Blackwell Max-Q Workstation Edition, RTX PRO 5000 Blackwell, RTX PRO 4500 Blackwell, and RTX PRO 4000 Blackwell
Lamp GPU: RTX PRO 5000 Blackwell, RTX PRO 4000 Blackwell, RTX PRO 3000 Blackwell, RTX PRO 2000 Blackwell, RTX PRO 1000 Blackwell and RTX PRO 500 Blackwell
Data Center GPU: NVIDIA RTX PRO 6000 Blackwell Server Edition
NVIDIA AI "family bucket" for enterprise-level computing
The above is only partially based on Blackwell Ultra chips are customized for different scenarios, from workstations to data center clusters, Nvidia will use them by itself.It is called "Blackwell Family" (Blackwell Family), and it is very suitable for Chinese translation "Blackwell Family Bucket".
Nvidia Photonics: The concept of a CPO system standing on the shoulders of teammatesThe concept of an optical co-packaging module (CPO) is simply to package the switch chip and optical module, which can convert optical signals into electrical signals and make full use of the transmission performance of optical signals.
Before this, the industry has been discussing Nvidia's CPO network switch products, but it has not been launched for a long time. Huang Renxun also gave an explanation on the spot - due to the large number of optical fiber connections in data centers, the power consumption of the optical network is equivalent to 10% of the computing resources, and the cost of optical connections directly affects the improvement of the performance density of the Scale-Out network and AI of the computing nodes.
Two silicon optical co-sealing chips Quantum-X and Spectrum-X parameters displayed on GTC
This year's GTC NVIDIA launched the Quantum-X silicon optical co-sealing chip, Spectrum-X silicon optical co-sealing chip and three derivative switch products: Quantum 3450-LD, Spectrum SN6810 and Spectrum SN6800.
Quantum 3450-LD: 144 800GB/s ports, backplane bandwidth of 115TB/s, liquid cooling
Spectrum SN6810: 128 800GB/s ports, backplane bandwidth of 102.4TB/s, liquid cooling
Spectrum SN6800: 512 800GB/s ports, backplane bandwidth of 409.6TB/s, liquid cooling
Spectrum SN6800: 512 800GB/s ports, backplane bandwidth of 409.6TB/s, liquid cooling
Spectrum SN6800: 512 800GB/s ports, backplane bandwidth of 409.6TB/s, liquid cooling
The above products are classified as "NVIDIA Photonics". NVIDIA said this is a platform based on the CPO partner ecosystem co-creation and research and development. For example, the micro-ring modulator (MRM) it is equipped with is based on TSMC's optical engine optimization, which supports high power,High-efficiency laser modulation and uses a removable fiber connector.
What is more interesting is that according to previous industry data, TSMC's micro-ring modulator (MRM) is built with Broadcom based on advanced packaging technologies such as 3nm process and CoWoS.
According to the data provided by Nvidia, Photonics switches that integrate optical modules have a performance improvement of 3.5 times, a deployment efficiency improvement of 1.3 times, and an expansion elasticity of more than 10 times compared to traditional switches.
Model efficiency PK DeepSeek: Software ecology focuses on AI AgentHuang Renxun depicts AI infra's "big cake" on the spot
Because on this 2-hour GTC, Huang Renxun only talks about about half an hour of software and embodied intelligence. Therefore, many details are supplemented through official documents, rather than from the scene.
1) Nvidia Dynamo, the new CUDA built by Nvidia in the field of reasoning is definitely the king of software released in this game.It is an open source software built for inference, training and acceleration across the entire data center. Dynamo's performance data is quite shocking: Dynamo can double the performance of the standard Llama model on the existing Hopper architecture. For special inference models such as DeepSeek, NVIDIA Dynamo's intelligent inference optimization can also increase the number of tokens generated by each GPU by more than 30 times.
Huang Renxun demonstrated that the Blackwell of Dynamo can exceed 25 times that of Dynamo
These improvements of Dynamo are mainly due to distribution. It allocates different computing stages of LLM (understanding user queries and generating optimal responses) to different GPUs, allowing each stage to be independently optimized, increasing throughput and speeding up response.
Dynamo's system architecture
For example, in the input processing stage, that is, the pre-filling stage, Dynamo can efficiently allocate GPU resources to process user input. The system will use multiple sets of GPUs to process user queries in parallel, hoping that the GPU will process more scattered and faster. Dynamo uses FP4 mode to call multiple GPUs to "read" and "understand" users' problems simultaneously. One group of GPUs handles the background knowledge of "World War II", another group of historical data related to "cause", and the third group of "passed" timelines and events. This stage is like multiple research assistants reviewing a large amount of data at the same time.
In the generation of output tokens, that is, the decoding stage, the GPU needs to be more focused and coherent. Compared with the number of GPUs, this stage requires more bandwidth to absorb the thinking information from the previous stage, and therefore more cached reads are required. Dynamo optimizes inter-GPU communication and resource allocation to ensure coherent and efficient response generation. On the one hand, it fully utilizes the high-bandwidth NVLink communication capabilities of the NVL72 architecture to maximize token generation efficiency. On the other hand, the request is directed to the GPU with cached related KVs (key values) through "Smart Router", which can avoid repeated calculations and greatly improve processing speed. Due to avoiding duplicate computing, some GPU resources are freed out Dynamo can dynamically allocate these free resources to new incoming requests.
This architecture is very similar to Kimi's Mooncake architecture, but Nvidia has made more support on the underlying infra. Mooncake can be improved by about 5 times, but Dynamo has improved more significantly in reasoning.
For example, among several important innovations of Dynamo, "GPU Planner" can dynamically adjust GPU allocation according to load, "low-latency communication library" optimizes data transmission between GPUs, while "memory manager" intelligently moves inference data between storage devices at different cost levels, further reducing operating costs. Smart routers, LLM-aware routing systems, direct requests to the most suitable GPU, reducing duplicate calculations. This series of capabilities optimizes the load on the GPU.
Using this software inference system can efficiently scale to large GPU clusters, allowing a single AI query to seamlessly scale up to 1,000 GPUs to make full use of data center resources.
For GPU operators, this improvement has significantly reduced the cost per million tokens, and a significant increase in production capacity. At the same time, a single user gets more tokens per second, which can respond faster and improve user experience.
Use Dynamo to enable servers to reach the golden return line between throughput and response speed
Left;"> Unlike CUDA as the underlying foundation of GPU programming, Dynamo is a higher-level system focusing on intelligent allocation and management of large-scale inference loads. It is responsible for the distributed scheduling layer of inference optimization, located between the application and the underlying computing infrastructure. But just as CUDA completely changed the GPU computing landscape more than a decade ago, Dynamo may also successfully create a new paradigm for inference hardware and software efficiency.
Dynamo is fully open source and supports all mainstream frameworks from PyTorch to Tensor RT. Open source is still a moat. Like CUDA, it only works on NVIDIA's GPU and is part of the NVIDIA AI inference software stack.
Using this software upgrade, NVIDIA built its own city defense against Groq and other dedicated inference AISC chips. It is necessary to match soft and hard to dominate the inference infrastructure.
2) The new Llama Nemotron model shows efficient, but it still cannot beat DeepSeekAlthough Dynamo is indeed quite amazing in server utilization, NVIDIA is still a bit different from a real expert in training models.
NVIDIA uses a new model Llama on GTC this time Nemotron, focusing on efficiency and accuracy. It is derived from the Llama series model. After special tuning by NVIDIA, compared with the Llama ontology, this model has been trimmed and optimized by algorithms and is lighter, with only 48B. It also has inference capabilities similar to O1. Like Claude 3.7 and Grok 3, the Llama Nemotron model has built-in inference capability switches, and users can choose whether to turn it on. This series is divided into three levels: the entry-level Nano, the mid-range Super and the flagship Ultra, each of which is aimed at the needs of different sizes of enterprises.
Llama Nemotron's specific data
Speaking of efficiency, the fine-tuning data set of this model is composed of Nvidia's own synthetic data, with a total of about 60B tokens. Compared with DeepSeek V3, it took 360,000H100 hours to be fully trained compared to DeepSeek V3's 1/15 parameters. The training efficiency is one level worse than DeepSeek.
In terms of inference efficiency, the Llama Nemotron Super 49B model does perform much better than the previous generation model, and its token throughput can reach Llama 3 70B 5 times that of a single data center GPU, it can throughput more than 3000 tokens per second. However, in the data released on the last day of DeepSeek open source day, the average throughput of each H800 node during pre-filling is about 73.7k tokens/s input (including cache hits) or about 14.8k tokens/s output during decoding. The gap between the two is still obvious.
From the performance point of view, the 49B Llama Nemotron Super surpasses the 70B Llama 70B model distilled by DeepSeek R1 in all metrics. However, considering the recent Qwen QwQ Small parameter high-energy models such as 32B models are frequently released, and Llama Nemotron Super is unlikely to be outstanding in these models that can compete with R1 ontology.
The most serious thing is that this model is equivalent to a solid demonstration of DeepSeek's knowledge of training GPUs than Nvidia.
3) The new model is just the starter of Nvidia's AI Agent ecosystem, and NVIDA AIQ is the main meal. Why did Nvidia develop an inference model? This is mainly for the next explosive point of AI that Lao Huang is interested in - AI Agent is preparing. Since OpenAI, Claude and other major manufacturers have gradually established the foundation of Agent through DeepResearch and MCP, NVIDA obviously believes that the Agent era has arrived.NVIDA AIProject Q is Nvidia's attempt. It directly provides an AI Agent off-the-shelf workflow for planners with the Llama Nemotron inference model as the core. This project belongs to NVIDIA's Blueprint level, which refers to a set of pre-configured reference workflows and templates, helping developers more easily integrate NVIDIA's technologies and libraries. AIQ is the Agent template provided by Nvidia.
NVIDA AIQ architecture
Like Manus, it integrates external tools such as online search engines and other professional AI agents, which allows the agent itself to search and use various tools. Through the planning, reflection and optimization of the processing scheme of the Llama Nemotron inference model, the user's tasks are completed. In addition, it also supports the construction of workflow architectures of multiple agents.
The servicenow system based on this template
A step further than Manus is that it has a complex RAG system for enterprise files. This system includes a series of steps of extraction, embedding, vector storage, and rearrangement to the final processing through LLM, which can ensure that the enterprise data is used by the Agent.
Above this, Nvidia has also launched an AI data platform to connect the AI inference model to the enterprise data system to form a DeepResearch for enterprise data. This has led to a significant evolution of storage technology, so that storage systems are no longer just data warehouses, but intelligent platforms with active reasoning and analysis capabilities.
The composition of AI Data Platform
In addition, AIQ emphasizes observability and transparency mechanisms very much. This is very important for security and subsequent improvements. The development team can monitor the activities of the Agent in real time and continuously optimize the system based on performance data.
Overall, NVIDA AIQ is a standard Agent workflow template that providesVarious Agent abilities. It is a more foolish Dify-like Agent construction software that evolved into the age of reasoning.
Basic model of humanoid robots is released. Nvidia wants to create a fully closed loop of embodied ecology. 1) Cosmos, so that embodied intelligence can understand the world.If focusing on agents or betting on the present, then Nvidia's layout in embodied intelligence can be regarded as an integration of the future.
Nvidia has arranged all three elements of model, data, and computing power.
Let's start with the model. This time, GTC released an upgraded version of the embodied intelligent basic model Cosmos, which was announced in January this year.
Cosmos is a model that can predict future images through the present images. It can input data from text/images, generate detailed videos, and predict the evolution of the scene by combining its current state (image/video) with actions (prompt/control signals). Because this requires an understanding of the physical causal laws of the world, Nvidia calls Cosmos the basic model of the world (WFM).
The basic architecture of Cosmos
For embodied intelligence, predicting what impact the behavior of a machine will have on the outside world is the core ability. Only in this way can the model plan behavior based on predictions, so the world model becomes the basic model of embodied intelligence. With this basic behavior/time-physical world-changing world prediction model, through fine-tuning of specific data sets such as autonomous driving and robot tasks, this model can meet the actual implementation needs of various embodied intelligences with physical forms.
The entire model contains three parts of capabilities. The first part Cosmos Transfer converts structured video text input into controllable real-life video output, and uses text to generate large-scale synthetic data out of thin air. This solves the biggest bottleneck of embodied intelligence - the problem of insufficient data. Moreover, this generation is a kind of "controllable" generation, which means that users can specify specific parameters (such as weather conditions, object properties, etc.), and the model will adjust the generation results accordingly, making the data generation process more controllable and targeted. The entire process can also be combined by Ominiverse and Cosmos.
Cosmos Realistic Simulation built on Ominiverse
Part 2 Cosmos Predict is able to generate virtual world states from multimodal inputs, supporting multi-frame generation and action trajectory prediction. This means that given the start and end states, the model can generate reasonable intermediate processes. This is the core physical world cognition and construction capability.
Part 3 is Cosmos Reason, an open and fully customizable model with space-time perception, understanding video data through thinking chain inference and predicting interaction results. This is the ability to plan behavior and predict behavior results.
This basic model should indeed have a good effect. In just two months of its launch, three leading companies, 1X, Agility Robotics, and Figure AI, have started to use it. The big language model is not leading, but the embodied intelligent NVIDIA is indeed in the first echelon.
2) Isaac GR00T N1, the world's first basic model of humanoid robotsWith Cosmos, NVIDIA naturally used this framework to fine-tune the basic model Isaac GR00T, which is dedicated to humanoid robots. N1.
Isaac GR00T N1's dual-system architecture
It uses a dual-system architecture, with a fast response "System 1" and a deep reasoning "System 2". Its comprehensive fine-tuning allows it to handle common tasks such as crawling, moving, and two-arm operation. It can also be fully customized based on the specific robot, and robot developers can use real or synthetic data for post-training. This allows this model to be actually deployed in a variety of robots of different shapes.
For example, Nvidia and Google DeepMind and Disney collaborate on the development of the Newton physics engine.I used the Isaac GR00T N1 as the base to drive a very unusual little Disney BDX robot. It can be seen that its versatility is very strong. Newton is very delicate as a physics engine, so it is enough to build a physical reward system to train embodied intelligence in a virtual environment.
Huang Renxun interacted with the "passionate" on the BDX robot stage
4) data generation, and a two-pronged approach was made by NVIDIA Omniverse and the above-mentioned NVIDIA Cosmos Transfer world basic model to create the Isaac GR00T Blueprint. It can generate a large amount of synthetic action data from a small number of human demonstrations for robot operation training. NVIDIA used Blueprint's first components to generate 780,000 synthetic trajectories in just 11 hours, equivalent to 6,500 hours (about 9 months) of human demonstration data. This is a considerable portion of the data of the Isaac GR00T N1, which makes the performance of the GR00T N1 40% higher than using only real data.Twin simulation system
For each model, Nvidia can provide a large amount of high-quality data with the pure virtual system of Omniverse and the real-world image generation system of Cosmos Transfer. Nvidia also covers the second aspect of this model.
3) The trinity computing power system creates a robot computing empire from training to end.Since last year, Lao Huang has emphasized the concept of "three computers" on GTC: one is DGX, which is a server for large GPUs, which is used to train AI, including embodied intelligence. Another AGX is an embedded computing platform designed by NVIDIA for edge computing and autonomous systems. It is used to specifically deploy AI on the end side, such as as the core chip of autonomous driving or robots. The third one is the data generation computer Omniverse+Cosmos.
Three major computing systems with embodied intelligence
This system was re-mentioned by Lao Huang in this GTC, and it is particularly mentioned that this computing power system can produce a billion-level robot. From training to deployment, computing power is used by Nvidia. This part is also closed.
ConclusionIf you simply compare the previous generation of Blackwell chips, Blackwell Ultra does not match the previous adjectives such as "nuclear bomb" and "king bomb" in hardware, and it even tastes like toothpaste.
Comparing with the hardware level, NVIDIA has made great progress in the software level in the past two years.
left;">Looking at Nvidia's entire software ecosystem, services at the three levels of Meno, Nim, and Blueprint include the full-stack solutions for model optimization and model encapsulation into application construction. The niche of Nvidia AI of cloud service companies all overlaps. With the newly added Agent and AI infra, Nvidia has to eat all parts except the basic model.
In the software part, Lao Huang's appetite is as big as Nvidia's stock price.
In the robot market, Nvidia has greater ambitions. The three elements of model, data, and computing power are all in their hands. They fail to catch up with the top spot in the basic language model, and the basic embodied intelligence is filled. A monopoly giant with an embodied intelligent version has emerged on the horizon.
In this, every link and every product correspond to a potential 100 billion market. Huang Renxun, the lucky gambling king who was desperate in the early years, began to make a bigger bet with the money obtained from GPU monopoly.
If in this bet, the software or robot market will take all of it, then Nvidia is Google in the AI era and the top monopoly in the food chain.
But look at the profit margin of Nvidia GPU, we stillLooking forward to such a future, don't come.
Fortunately, for Lao Huang's life, this is a big bet that he has never traded before, and the outcome is unpredictable.
