









23 mins ago
1,562
Compiled by: Jiayu, Cage
AI Agent is a paradigm change that we are tracking closely, and a series of articles by Langchain are very helpful in understanding the development trends of Agent. In this compilation, the first part is the State of AI Agent report released by the Langchain team. They interviewed more than 1,300 practitioners, including developers, product managers, and company executives, revealing the current situation and implementation bottlenecks of Agent this year: 90% of companies have plans and needs for AI Agents, but the limitations of Agent capabilities make it difficult for users to It can only be implemented in a few processes and scenarios. Rather than cost and latency, everyone cares more about the improvement of Agent capabilities and the observability and controllability of its behavior.
In the second part, we compiled the analysis of the key elements of AI Agent from the In the Loop series of articles on the LangChain official website: planning capabilities, UI/UX interaction innovation and memory mechanism. This article analyzes the interaction methods of 5 LLM-native products, analogizes 3 complex human memory mechanisms, and provides some inspiration for understanding AI Agent and these key elements. In this part, we have also added some representative Agent company case studies, such as interviews with the founders of Reflection AI, to look forward to the key breakthroughs of AI Agent in 2025.
Under this analysis framework, we expect that AI Agent applications will begin to emerge in 2025, entering a new paradigm of human-machine collaboration. Regarding the planning capabilities of AI Agents, models headed by o3 are showing strong reflection and reasoning capabilities, and the progress of model companies is approaching the stage from reasoner to agent. As reasoning capabilities continue to improve, the “last mile” of Agents will be product interaction and memory mechanisms, which are more likely to be opportunities for startups to break through. Regarding interaction, we have been looking forward to the "GUI moment" in the AI era; regarding memory, we believe Context will become the key word for Agent implementation. Context personalization at the personal level and context unification at the enterprise level will greatly improve Agent's product experience.
01.Agent usage trend:
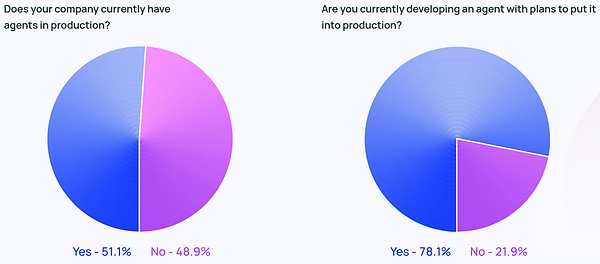
Every company is planning to deploy Agent
p>
Competition in the Agent field is becoming fierce. Over the past year, many agent frameworks have become popular: for example using ReAct combined with LLM for reasoning and action, using multi-agent frameworks for orchestration, or using more controllable frameworks like LangGraph.
The buzz around Agent isn't all Twitter hype. Approximately 51% of respondents are currently using Agent in production. According to Langchain's data by company size, medium-sized companies with 100-2000 employees are the most active in putting Agent into production, with a proportion of 63%.
In addition, 78% of respondents have plans to put Agent into production in the near future. Obviously, everyone has a strong interest in AI Agent, but actually making a production-ready Agent is still a difficult problem for many people.
Although the technology industry is often considered to be early adopters of Agent, all industries are interested in Agent's interest is growing day by day. 90% of respondents who work for non-tech companies have already put or plan to put agents into production (almost the same percentage as technology companies, 89%).
Agent’s commonly used use cases
Agent’s most commonly used use cases include research and summary (58%), followed by simplification of work processes through customized Agents (53.5%).
These reflect people's desire for products to handle tasks that are too time-consuming. users can rely onAI Agent extracts key information and insights from large amounts of information, rather than sifting through massive amounts of data and then conducting data review or research analysis. Likewise, AI Agents can increase personal productivity by assisting with daily tasks, allowing users to focus on what matters.
Not only individuals need this kind of efficiency improvement, but companies and teams also need it. Customer service (45.8%) is another main application area of Agent. Agent helps companies handle consultations, troubleshooting, and speed up customer response times across teams; ranking fourth and fifth are lower-level code and data applications.
Monitoring: Agent applications require observability and controllability
As Agent implementation functions become more powerful, methods for managing and monitoring Agents are needed. Tracing and observability tools top the must-have list to help developers understand the behavior and performance of agents. Many companies also use guardrail (guard controls) to prevent agents from going off track.
When testing LLM applications, offline evaluation (39.8%) is better than online evaluation ( 32.5%) were used more frequently, reflecting the difficulty of monitoring LLM in real time. Among the open-ended responses provided by LangChain, many companies also have human experts manually review or evaluate responses as an additional layer of prevention.
Although people are very enthusiastic about Agents, they are generally conservative in terms of Agent permissions. Few respondents allow their agents to read, write, and delete freely. Instead, most teams only allow tool permissions with read access, or require human approval before the agent can do riskier actions like writing or deleting.
Companies of different sizes also have different priorities in Agent control. Unsurprisingly, large enterprises (2,000+ employees) are more cautious and rely heavily on “read-only” permissions to avoid unnecessary risks. They also tend to combine guardrail protection with offline assessments and don't want customers to see anyWhat problem.
At the same time, small companies and startups (fewer than 100 employees) are more Focus on tracing to understand what is happening in their Agent application (rather than other controls). According to LangChain survey data, smaller companies tend to focus on looking at the data to understand the results; while larger enterprises have more controls in place across the board.
Obstacles and challenges in putting Agent into production
It is difficult to ensure high-quality performance of LLM. Answers need to be highly accurate and consistent with the correct style. This is the biggest concern of Agent developers and users - more than twice as important as cost, security and other factors.
LLM Agent is a probabilistic content output, which means strong unpredictability. This introduces more potential for error, making it difficult for teams to ensure their agents consistently provide accurate, contextual responses.
This is especially true for smaller companies, where performance quality far outweighs other considerations, with 45.8% cited this as their main concern, while cost (the second largest concern) was only 22.4%. This gap underscores the importance of reliable, high-quality performance for organizations moving Agents from development to production.
Security issues are also prevalent for large companies that require strict compliance and handle customer data sensitively.
The challenge goes beyond quality. From the open-ended answers provided by LangChain, many people remain skeptical about whether the company will continue to invest in developing and testing Agents. Everyone mentioned two outstanding obstacles: developing Agents requires a lot of knowledge and keeps up to date with the technological frontier; developing and deploying Agents requires a lot of time and costs, and the benefits of reliable operation are uncertain.
Other emerging topics
p>In the open questions, everyone praised the capabilities demonstrated by the AI Agent:
•Manage multi-step tasks: AI Agents are capable of deeper reasoning and context management, enabling them to handle more complex tasks;
•Automate repetitive tasks :AI Agent Continues to be seen as key to automating tasks, freeing up users’ time to solve more creative problems;
Task planning and collaboration: Better task planning ensures that the right Agent handles the right problem at the right time, especially in Multi-agent systems;
•Human-like reasoning: Unlike traditional LLM, AI Agent can trace its decisions, including reviewing and modifying past decisions based on new information.
In addition, there are two most anticipated developments:
•Open source AI Agent Expectations: People are obviously interested in open source AI Agents, and many people mentioned that collective intelligence can accelerate Agent innovation;
•Expectations for more powerful models: Many are looking forward to AI agents driven by larger, more powerful models The next leap forward—when Agents can handle more complex tasks with greater efficiency and autonomy.
Many people in the Q&A also mentioned the biggest challenge in Agent development: how to understand Agent behavior. Some engineers mentioned they had difficulty explaining the AI Agent's capabilities and behavior to company stakeholders. Sometimes visualization plug-ins can help explain Agent behavior, but in more cases LLM is still a black box. The additional interpretability burden is left to the engineering team.
02. Core elements in AI Agent
What is Agentic system
atBefore the release of the State of AI Agent report, the Langchain team had written its own Langraph framework in the Agent field and discussed many key components in AI Agent through the In the Loop blog. Next is our compilation of the key contents.
First of all, everyone has a slightly different definition of AI Agent. Harrison Chase, founder of LangChain, gave the following definition:
AI Agent is a system that uses LLM to make program control flow decisions.
An AI agent is a system that uses an LLM to decide the control flow of an application.
As for its implementation, the article introduces the concept of Cognitive architecture. Cognitive architecture refers to how the Agent thinks and how the system arranges code/prompt LLM: p>
• Cognitive: Agent uses LLM to semantically reason about how to arrange code/Prompt LLM;
•Architecture: These Agent systems still involve a lot of engineering similar to traditional system architecture.
The picture below shows examples of different levels of Cognitive architecture:
•Standardized software code (code): Everything is Hard Code, and the relevant parameters of output or input are directly fixed in the source code. This does not constitute a cognitive architecture. Because there is no cognitive part;
•LLM Call, except for some data preprocessing, a single LLM call constitutes most of the application. SimpleChatbot belongs to this category;
•Chain: a series of LLM calls. Chain tries to divide the solution of the problem into several steps and calls different LLM to solve the problem. Complex RAGs fall into this category: the first LLM is called to search and query, and the second LLM is called to generate answers;
•Router: in In the previous three systems, users can know all the steps that the program will take in advance, but in Router, LLM decides by itself which LLM to call and what steps to take, which adds more randomness and unpredictability; p>
•State Machine, using LLM in combination with Router will be more unpredictable, because when combined in a loop, the system can (theoretically) make unlimited LLM calls;
•Agentic's system: Everyone will also call it "Autonomous Agent". When using State Machine, there are still restrictions on what operations can be taken and what processes are performed after performing the operation; but when using These restrictions will be removed when using Autonomous Agent. LLM to decide which steps to take and how to orchestrate different LLMs. This can be done by using different prompts, tools or code.
Simply put, the more "agentic" a system is, the more LLM determines how the system behaves.
Key elements of Agent
Planning
Agent reliability is a big pain point. There are often companies that use LLM to build Agents, but mention that the Agent cannot plan and reason well. What do planning and reasoning mean here?
Agent's planning and reasoning refer to the LLM's ability to think about what actions to take. This involves short-term and long-term reasoning, where the LLM evaluates all available information and then decides: What series of steps do I need to take, and which are the first steps I should take now?
Many times developers use Function calling to let LLM choose the operation to perform. Function calling is a capability that OpenAI first added to the LLM API in June 2023. With Function calling, users can provide JSON structures for different functions and let LLM match one (or more) of these structures.
To successfully complete a complex task, the system needs to take a series of actions in sequence. This kind of long-term planning and reasoning is very complicated for LLM: first, LLM must consider a long-term action plan, and then return to the short-term actions to be taken; secondly, as the Agent performs more and more operations, the results of the operations will be fed back to LLM, causing the context window to grow, which may cause LLM to "distract" and perform poorly.
The easiest solution to improve planning is to ensure that the LLM has all the information needed for proper reasoning/planning. Although this sounds simple, often the information passed to the LLM is simply not enough for the LLM to make a reasonable decision, and adding a retrieval step or clarifying the Prompt might be a simple improvement.
Afterwards, you can consider changing the cognitive architecture of your application. There are two types of cognitive architectures to improve reasoning, general cognitive architectures and domain-specific cognitive architectures:
1. General cognitive architecture
General cognitive architecture can be applied to any task. There are two papers here that propose two general architectures. One is the "plan and solve" architecture, which is proposed in the article Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models. In the architecture, the agent first proposes a plan and then executes each step in the plan. Another common architecture is the Reflexion architecture, proposed in Reflexion: Language Agents with Verbal Reinforcement Learning. In this architecture, the Agent has a clearA "reflection" step to reflect whether it performed the task correctly. I won’t go into details here, but you can read the two papers for details.
While these ideas show improvements, they are often too general to be actually used by Agents in production. (Translator’s Note: There was no o1 series model when this article was published)
2. Cognitive architecture in specific fields
Instead, we see that the Agent is built using domain-specific cognitive architecture. This usually manifests itself in domain-specific classification/planning steps, domain-specific validation steps. Some ideas from planning and reflection can be applied here, but they are usually applied in a domain-specific way.
A paper from AlphaCodium gives a specific example: by using what they call "stream engineering" (another way of talking about cognitive architecture) State-of-the-art performance achieved.
You can see that the Agent's process is very specific to the problem they are trying to solve. They tell the Agent what to do in steps: come up with tests, then come up with solutions, then iterate with more tests, etc. This cognitive architecture is highly focused on a specific field and cannot be generalized to other fields.
Case Study:
Reflection AI founder Laskin’s vision for the future of Agent
In an interview with Reflection AI founder Misha Laskin from Sequoia Capital, Misha mentioned that he is beginning to realize his vision: by combining RL's Search Capability with LLM Combined, at his new company Reflection AI Build the best Agent model. He and co-founder Ioannis Antonoglou (head of AlphaGo, AlphaZero, Gemini RLHF) are training models designed for Agentic Workflows. The main points in the interview are as follows:
• Depth isThe missing piece in AI Agent. While current language models excel in terms of breadth, they lack the depth needed to reliably complete the task. Laskin believes that solving "deep problems" is crucial to creating truly capable AI agents, where capabilities refer to agents that can plan and execute complex tasks through multiple steps;
•Combining Learn and Search is the key to achieving superhuman performance. Drawing on the success of AlphaGo, Laskin emphasized that the most profound idea in AI is the combination of Learn (relying on LLM) and Search (finding the optimal path). This approach is critical for creating agents that can outperform humans at complex tasks;
• Post-training and Reward modeling pose significant challenges. Unlike games with clear rewards, real-world tasks often lack real rewards. Developing reliable reward models is a key challenge in creating reliable AI Agents
• Universal Agents may be closer than we think. Laskin estimates that we may have just three years to achieve “digital AGI,” AI systems with both breadth and depth. This accelerated timeline highlights the urgency of addressing security and reliability issues while developing capabilities
•The path to Universal Agents requires a method. Reflection AI focuses on extending Agent functionality, starting with specific environments such as browsers, coding, and computer operating systems. Their goal is to develop Universal Agents that are not limited to specific tasks.
UI/UX interaction
In the next few years, human-computer interaction will become the focus of research One key area: Agent systems differ from traditional computer systems of the past because latency, unreliability, and natural language interfaces pose new challenges. As a result, new UI/UX paradigms for interacting with these Agent applications will emerge. Agent systems are still in their early stages, but there are already several emerging UX paradigms emerging. Discuss separately below:
1. Conversational interaction (Chat UI)
Chat is generally divided into two types: streaming chat ), non-streaming Chat.
Streaming chat is by far the most common UX. It is a Chatbot that streams its thoughts and actions back in a chat format - ChatGPT being the most popular example. This interaction mode seems simple, but it also has good results because: first, natural language can be used to talk to the LLM, which means there are no obstacles between the customer and the LLM; second, the LLM may take a while to work, Streaming allows users to understand exactly what is happening in the background; third, LLM often makes mistakes, and Chat provides a great interface to correct and guide it naturally, and everyone has become very accustomed to having subsequent conversations and iterations in chat. Discuss things.
But streaming chat also has its drawbacks. First, streaming chat is a relatively new user experience, so our existing chat platforms (iMessage, Facebook Messenger, Slack, etc.) don't have it; second, for longer-running tasks, this is a bit Awkward—Does the user just have to sit there and watch the Agent work? Third, streaming chat usually needs to be triggered by a human, which means a lot of humans are needed in the loop.
The biggest difference in non-streaming chat is that responses are returned in batches, LLM works in the background, and users are not eager for LLM to answer immediately, which means it May be easier to integrate into existing workflows. People are already used to texting humans – why can’t they adapt to texting with AI? Non-streaming chat will make it easier to interact with more complex Agent systems—these systems often take a while, which can be frustrating if instant responses are expected. Non-streaming chat often removes this expectation, making it easier to perform more complex things.
These two chat methods have the following advantages and disadvantages:
2. Background environment (Ambient UX)
Users will consider sending messages to AI, which is the Chat mentioned above, but if the Agent only works in the background, how should we interact with the Agent?
For Agent systems to truly reach their potential, there needs to be this shift that allows AI to work in the background. Users are generally more tolerant of longer completion times when tasks are processed in the background (because they relax their expectations for lower delayed expectations). Frees up time to do more work, often more careful and diligent reasoning than in a chat UX
Furthermore, running the Agent in the background can scale. The capabilities of our human users. Chat interfaces typically limit us to performing one task at a time. However, if an Agent is running in a background environment, there may be many Agents handling multiple tasks simultaneously.
Let Agent Running in the background requires user trust. How to build this trust? A simple idea is to show the user exactly what the agent is doing, and let the user observe what is happening. These steps may not be immediately visible (like when streaming a response), but it should be available for the user to click on and observe. The next step is to not only let the user see what's going on, but also let them correct the agent if they notice. Agent in step 4 of 10 If an incorrect choice is made in step 4, the client can choose to return to step 4 and correct the Agent in some way.
This approach removes the user from "In." -the-loop" to "On-the-loop". "On-the-loop" requires being able to show the user all the intermediate steps performed by the Agent, allowing the user to pause the workflow midway, provide feedback, and then let the Agent continue. < /p>
AI Devin for Software Engineer is an application that implements a similar UX. Devin is longer running, but the client can see all the steps taken, rewind the development status at a specific point in time, and issue corrections from there although the Agent may be running in the background. , but this does not mean that it needs to perform tasks completely autonomously. Sometimes the Agent does not know what to do or how to answer. At this time, it needs to attract human attention and ask for help.
A specific example is Harrison The email assistant Agent being built. While the email assistant can reply to basic emails, it often requires Harrison to input certain tasks that he doesn't want to automate, including: reviewing complex LangChain bug reports, deciding whether to attend a meeting, and more. In this case, the email assistant needs a way to communicate to Harrison that it needs information to respond. Note that it's not asking for a direct answer; instead, it's asking Harrison for his input on certain tasks, which it can then use to craft and send a nice email or schedule a calendar invite.
Currently, Harrison has the assistant set up in Slack. It sends a question to Harrison, who answers it in the Dashboard, natively integrated with its workflow. This type of UX is similar to the UX of a customer support dashboard. This interface will display all areas where the assistant requires human help, the priority of the request, and any other data.
3. Spreadsheet (Spreadsheet UX)
Spreadsheet UX is a super intuitive and user-friendly way to support batch processing work. Each table and even each column becomes its own Agent to study specific things. This batch processing allows users to scale interactions with multiple Agents.
This UX has other benefits as well. The spreadsheet format is a UX that most users are familiar with, so it fits well into existing workflows. This type of UX is ideal for data enrichment, a common LLM use case, where each column can represent a different attribute to be enriched.
Exa AI, Clay AI, Manaflow and other companies' products are all using this UX. The following uses Manaflow as an example to show how this spreadsheet UX handles the workflow.
Case Study:
How Manaflow uses spreadsheets for Agent interaction
Manaflow is inspired by Minion AI, the company where founder Lawrence once worked. The product built by Minion AI is Web Agent. The Web Agent can control the local Geogle Chrome, allowing it to interact with applications such as booking flights, sending emails, scheduling car washes, and more. Based on the inspiration of Minion AI, Manaflow chose to let Agent operate spreadsheet-like tools. This is because Agent is not good at processing human UI interfaces. What Agent is really good at is Coding. Therefore, Manaflow allows the Agent to call the Python script of the UI interface, database interface, link API, and then directly operate the database: including reading time, booking, sending emails, etc.
The workflow is as follows: The main interface of Manaflow is a spreadsheet (Manasheet), in which each column represents a step in the workflow and each row corresponds to the execution AI Agent for the task. Each spreadsheet workflow can be programmed using natural language (allowing non-technical users to describe tasks and steps in natural language). Each spreadsheet has an internal dependency graph that determines the order in which each column is executed. These sequences will be assigned to each row of Agents to execute tasks in parallel and handle processes such as data conversion, API calls, content retrieval, and message sending:
The possible way to generate the Manasheet is: enter the natural language similar to the red box above. For example, if you want to send pricing emails to customers in the above picture, you can enter Prompt through Chat to generate the Manasheet. . Through the Manasheet, you can see the customer's name, customer's email, the customer's industry, whether the email has been sent, and other information; click Execute Manasheet to execute the task.
4. Generative UI (Generative UI)
"Generative UI" has two different implementation methods.
One way is to have the model generate the required original components by itself. This is similar to products like Websim. in the background, the Agent primarily writes raw HTML, giving it full control over what is displayed. But this approach allows for high uncertainty in the quality of the generated web app, so the end result may appear to be volatile.
Another more constrained method is to predefine some UI components. This is usually done through tool calls. For example, if LLM calls the Weather API, it triggers the rendering of the Weather Map UI component. Since the rendered components are not truly generated (but have more options), the generated UI will be more refined, although not entirely flexible in what it can generate.
Case Study:
Personal AI product dot
For example, Dot, which was once called the best Personal AI product in 2024, is a good generative UI product.
Dot is a product of New Computer: its goal is to become a long-term companion for users, not a better task management tool, according to co-founder Jason Yuan Well, the feeling of Dot is that you turn to Dot when you don't know where to go, what to do, or what to say. Here are two examples to introduce what the product does:
•Founder Jason Yuan often asks Dot to recommend bars late at night, saying that he wants to get drunk and rest. , on and off for several months, one day after get off work, Yuan asked similar questions again, and Dot actually began to persuade Jason that he could not continue like this;
•Fast Company reporter Mark Wilson, also with Dot Been together for several months. Once, he shared with Dot an "O" he had written in his calligraphy class. Dot actually pulled up a photo of his handwritten "O" a few weeks ago and praised his calligraphy for his improvement.
•As I use Dot more and more time, Dot understands better that users like to visit cafes, and proactively recommends good cafes near the owner. I asked why this cafe is so good, and finally asked thoughtfullyWhether to navigate.
As you can see in this cafe recommendation example, Dot LLM-native interactive effects are achieved through predefined UI components.
5. Collaborative UX
When Agents and humans work together what happens? Think of Google Docs, where customers can collaborate with team members to write or edit documents, but what if one of the collaborators is an Agent?
Geoffrey Litt’s Patchwork project with Ink & Switch is a great example of human-agent collaboration. (Translator's note: This may be the inspiration for the recent OpenAI Canvas product update).
How does collaborative UX compare to the Ambient UX discussed earlier? LangChain founding engineer Nuno emphasized that the main difference between the two is whether there is concurrency:
• In collaborative UX, customers and LLM often work at the same time , taking each other's work as input;
•In ambient UX, the LLM continues to work in the background while the user is focused on something else entirely.
Memory
Memory is crucial to a good Agent experience. Imagine if you had a colleague who never remembered what you told them, forcing you to repeat the information over and over again. This would be a very poor collaboration experience. People often expect LLM systems to have innate memories, perhaps because LLMs already feel a lot like humans. However, LLM itself cannot remember anything.
Agent's memory is based on the needs of the product itself, and different UX provides different methods to collect information and update feedback. We can use AgentDifferent advanced memory types are seen in the product's memory mechanism - they mimic human memory types.
The paper CoALA: Cognitive Architectures for Language Agents maps human memory types to Agent memory, and the classification method is as shown in the figure below:
1. Procedural Memory: long-term memory about how to perform tasks, similar to the brain’s core instructions Set
•Human procedural memory: remembering how to ride a bike.
•Agent's procedural memory: The CoALA paper describes procedural memory as the combination of LLM weights and Agent code, which fundamentally determine how the Agent works.
In practice, the Langchain team has not seen any Agent system automatically update its LLM or rewrite its code, but there are indeed some Agents that update their system prompts example.
2. Semantic Memory: Long-term knowledge reserve
•Human semantics Memory: It consists of pieces of information such as facts, concepts and the relationships between them learned in school.
•Agent's Semantic Memory: The CoALA paper describes semantic memory as a repository of facts.
In practice, this is often achieved by using LLM to extract information from the Agent's dialogue or interaction. Exactly how this information is stored is typically application-specific. This information is then retrieved in future conversations and inserted into System Prompts to influence the Agent's response.
3. Episodic Memory: recalling specific past events
•Human episodic memory: When a person recalls a specific event (or "episode") experienced in the past.
•Episode in Agent Memory: The CoALA paper defines episodic memory as storing the sequence of the agent's past actions.
This is mainly used to allow the agent to perform actions as expected. In practice, episodic memory. Updates via Few-Shots Prompt Method implementation. If there are enough related updated Few-Shots Prompt, then the next update is completed through Dynamic Few-Shots Prompt
If it is started. There is a way to guide the Agent to complete the operation correctly. You can use this method directly when facing the same problem later; on the contrary, if there is no correct operation method, or if the Agent If you keep doing new things, semantic memory will be more important, but in the previous example, semantic memory will not help much
Except for thinking about what to do. In addition to the types of memory updated in the Agent, developers also need to consider how to update the Agent's memory:
The first way to update the Agent's memory is "in the hot path". In this case, the Agent system remembers the fact before responding (usually via a tool call), ChatGPT takes this approach to update its memory;
Another way to update the Agent's memory is "in the background". In this case, the background process will. Run after session to update memory
Compare the two methods, "in the The disadvantage of the "hot path" approach is that there is some delay before any response is delivered, and it also requires combining memory logic with agent logic Combined.
However, "in the background" avoids these problems - no increase in latency, and the memory logic remains independent "in the backgroun".d" also has its own disadvantages: the memory is not updated immediately, and additional logic is required to determine when to start the background process.
Another way to update the memory The method involves user feedback, which is particularly relevant to episodic memory. For example, if the user rates an interaction high (Postive Feedback), the Agent can save that feedback for future recall.
Based on the above compiled content, we expect that the simultaneous progress of the three components of planning, interaction, and memory will allow us to see more available AI Agents in 2025 and enter a new era of human-machine collaborative work.