









48 mins ago
7,915
Article source: ASXN; Compilation: Golden Finance xiaozou
1. PrefaceMonad is a high-performance optimized EVM compatible with L1, with 10,000 TPS (1 billion gases per second), a block output frequency of 500 milliseconds and a finality of 1 second. The chain is built from scratch and aims to solve some of the problems faced by EVM. Specifically: EVM processes transactions in sequence, resulting in bottlenecks during high network activity, thereby extending transaction time, especially when network congestion.
*The throughput is low, only 12-15 TPS, and the block time is long, which is 12 seconds.
*EVM requires gas fees to be paid per transaction, and the fees fluctuate greatly, especially when network demand is high, gas fees can become extremely expensive.
2. Why extending EVMMonad provides complete EVM bytecode and Ethereum RPC API compatibility, allowing developers and users to integrate without changing existing workflows.
A common question is why you should extend EVM when there are alternatives that perform better like SVM. Compared to most EVM implementations, SVM provides faster blocking time, lower fees, and higher throughput. However, EVM has some key advantages that stem from two main factors: the large amount of capital in the EVM ecosystem and the extensive developer resources.
(1) Capital foundation
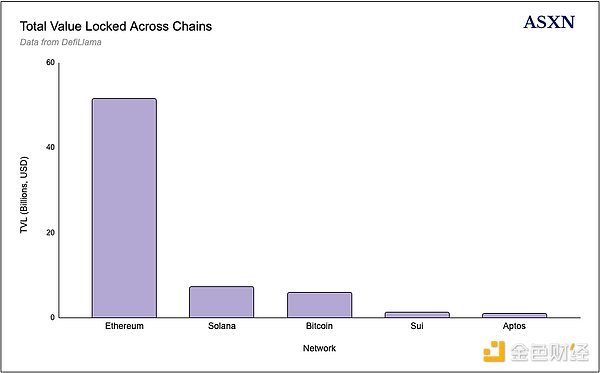
EVM has a large amount of capital, Ethereum's TVL is close to $52 billion, while Solana has $7 billion. L2, such as Arbitrum and Base, each hold about $2.5-3 billion in TVL. Monad and other EVM compatible chains can benefit from the large capital base on the EVM chain through specification and third-party bridges integrated with minimal friction. This huge EVM capital base is relatively active and can attract users and developers because:
*Users tend to be liquidity and high trading volume.
*Developers seek high transaction volume, fees and visibility of applications.
(2) Developer resources
Ethereum's tools and applied cryptography research are directly integrated into Monad, and at the same time, they obtain higher throughput and scale through the following methods:
*Applications
*Developer tools (Hardhat, Apeworx, Foundry)
*Wallet (Rabby, Metamask, Phantom)
*Analysis/Index (Etherscan, Dune)
Electric Capital's developer report shows that as of July 2024, Ethereum had 2,788 full-time developers, 889 Base, and 834 Polygon. Solana is ranked seventh with 664 developers, behind Polkadot, Arbitrum and Cosmos. Although some people believe that the total number of developers in the crypto field is still small and should be basically ignored (resources should be focused on introducing external talents), it is obvious that there are a large number of EVM talents in this "small" pool of crypto developers. Furthermore, given that most talent works in EVM and most tools are in EVM, new developers will most likely have to or choose to learn and develop in EVM. As Keone mentioned in an interview, developers can choose:
*Build portable applications for EVMs and enable multi-chain deployments, but with limited throughput and high cost.
*Build high-performance and low-cost applications in specific ecosystems such as Solana, Aptos, or Sui.
Monad aims to combine these two methods. Since most tools and resources are customized for EVMs, applications developed within their ecosystem can be ported seamlessly. Combining its relative performance and efficiency - thanks to Monad's optimization - EVM is obviously a strong competitive barrier.
exceptDevelopers and users also prefer familiar workflows. With tools such as Rabby, MetaMask and Etherscan, EVM workflow has become the standard. These mature platforms facilitate the integration of bridges and protocols. In addition, basic applications (AMM, money market, bridge) can be started immediately. These basic primitives are crucial for the sustainability of chains and for novel applications.
3. Extend EVMThere are two main methods to extend EVM:
*Move the execution off-chain: uninstall the execution to other virtual machines through rollups, adopting a modular architecture.
*Improving performance: Improve the performance of the EVM in the basic chain through consensus optimization and increasing block size and gas limits.
(1) Rollup and modular architecture
Vitalik introduced rollups as the main expansion solution for Ethereum in October 2020, in line with the principle of modular blockchain. Therefore, Ethereum's expansion roadmap delegates execution to rollups, which are off-chain virtual machines that take advantage of Ethereum's security. Rollup excels in execution, with higher throughput, lower latency and lower transaction costs. Their iterative development cycle is shorter than Ethereum—update that takes years on Ethereum may only take months on rollups because of the lower potential costs and losses.
Rollup can be run using a centralized sorter while maintaining a secure escape pod, helping them bypass certain decentralized requirements. It should be noted that many rollups (including Arbitrum, Base, and OP Mainnet) are still in their infancy (Stage 0 or Stage 1). In the rollup of Phase 1, fraud proof submission is limited to whitelisted participants, and escalations that are not related to on-chain proven errors must provide the user with a minimum of 30-day exit window. The rollup in phase 0 provides users with less than 7 days of exit time when the licensed operator is down or reviewed.
In Ethereum, the typical transaction size is 156 bytes and the signature contains the most data. Rollup allows multiple transactions to be bundled together, reducing overall transaction size and optimizing gas costs. In short, rollup submits multiple transactions to the Ethereum main network by packaging multiple transactions into batchesto achieve efficiency. This reduces on-chain data processing but increases ecosystem complexity, as rollup connections require new infrastructure requirements. In addition, rollup itself adopts a modular architecture, moving execution to L3 to solve the basic rollup throughput limitations, especially gaming applications.
Although rollup theoretically eliminates bridging and liquidity fragmentation by becoming a comprehensive chain above Ethereum, the current implementation has not yet become a fully "full" chain. By TVL, the three major rollups—Arbitrum, OP Mainnet and Base—maintain different ecosystems and user groups, each performing well in certain areas but failing to provide a comprehensive solution.
In short, users must access multiple different chains to get the same experience as using a single chain, such as Solana. The lack of unified shared state in the Ethereum ecosystem (one of the core propositions of blockchain) greatly limits on-chain use cases – especially due to the fragmentation of liquidity and state, competing rollups cannot easily understand each other’s state. State fragmentation also brings additional demand for bridge and cross-chain message protocols that can connect rollups and states together, but with some trade-offs. A single blockchain does not face these fragmentation problems because there is a single ledger record status.
Each rollup takes a different approach in optimizing and focusing on its specific domain. Optimism introduces additional modularity through Superchain, so it relies on other L2s to build with their stack and compete for a fee. Arbitrum focuses primarily on DeFi, especially perpetual and options exchanges, while expanding to L3 through Xai and Sanko. New high-performance rollups such as MegaETH and Base have emerged with higher throughput capabilities, designed to provide a single large chain. MegaETH has not yet been launched, and Base is impressive in implementation, but is still inadequate in some areas, including derivatives trading (options and perpetual) and DePIN areas.
(2) Early L2 expansion
Optimism and Arbitrum
The first generation of L2 provides improved execution compared to Ethereum, but lags behind the new hyper-optimization solution. For example, Arbitrum processes 37.5 transactions per second ("TPS") and Optimism Mainnet is11 TPS. By comparison, Base has about 80 TPS, MegaETH targets 100,000 TPS, BNB Chain has 65.1 TPS, and Monad targets 10,000 TPS.
Although Arbitrum and Optimism Mainnet cannot support extremely high throughput applications like full-on-chain order book, they extend through additional chain layers—Arbitrum's L3 and Optimism's hyperchain—and centralized sorters.
Arbitrum focuses on the L3, Xai and Proof of Play of the game, showing this approach. They are built on the Arbitrum Orbit stack and settled on Arbitrum using AnyTrust data availability. Xai hits 67.5 TPS, while Proof of Play Apex hits 12.2 TPS and Proof of Play Boss has 10 TPS. These L3s introduce additional trust assumptions through Arbitrum settlement, rather than the Ethereum mainnet, while facing the potential challenge of fewer decentralized data availability layers. Optimism's L2—Base, Blast and the upcoming Unichain—maintain greater security through Ethereum settlement and blob data availability.
Both networks prioritize horizontal scaling. Optimism provides L2 infrastructure, chain deployment support and shared bridges with interoperability capabilities through OP Stack. Arbitrum offloads specific use cases to L3, especially gaming applications, where the additional trust assumptions pose lower capital risks than financial applications.
(3) Optimize chain and EVM performance
Alternative scaling methods focus on performing optimizations or target trade-offs, increasing throughput and TPS by scaling vertically rather than horizontally. Base, MegaETH, Avalanche and BNB Chain embody this strategy.
BaseBase announced plans to reach 1 Ggas/s by gradually increasing gas targets. In September, they raised their target to 11 Mgas/s and increased the gas limit to 33 Mgas. The initial block processed 258 transactions, keeping about 70 TPS five hours. By December 18, the gas target will reach 20 Mgas/s, with a block production time of 2 seconds, and each block supports 40M gas. By comparison, Arbitrum has 7 Mgas/s and OP Mainnet has 2.5 MGas/s.
Base has become a competitor to Solana and other high-throughput chains. As of today, Base has surpassed other L2s in activities, specifically manifested as:
*As of January 2025, its monthly fee reached US$15.6 million - 7.5 times that of Arbitrum and 23 times that of OP Mainnet.
*As of January 2025, its transaction volume reached 329.7 million, 6 times that of Arbitrum (57.9 million) and 14 times that of OP Mainnet (24.5 million). Note: Trading volume may be manipulated and may be misleading.
The Base team focuses on providing a more unified experience by optimizing speed, throughput and low fees, rather than the modular approach of Arbitrum and Optimism. Users show preference for a more unified experience, as Base's activity and revenue figures show. In addition, Coinbase's support and distribution also help.
MegaETH
MegaETH is an EVM-compatible L2. At its core, it processes transactions through a hybrid architecture using dedicated sorter nodes. MegaETH uniquely separates performance and security tasks in its architecture, combining new state management systems to replace the traditional Merkle Patricia Trie to minimize disk I/O operations.
The system processes 100,000 transactions per second with a latency of less than milliseconds while maintaining full EVM compatibility and the ability to process TB-level state data. MegaETH uses EigenDA for data availability, and distributes functions across three dedicated node types:
*Sorter: a high-performance single node (100 cores, 1-4TB RAM) management transferEasy to sort and execute, keeping the state in RAM for quick access. It generates blocks at approximately 10 millisecond intervals, witnesses block verification, and tracks state differences in blockchain state changes. The sorter achieves high performance through parallel EVM execution and priority support without consensus overhead during normal operation.
*Proofer: These lightweight nodes (1 core, 0.5GB RAM) calculate the encryption proof of verification of block content. They asynchronously and out of order validate blocks, adopt stateless verification, horizontal scaling, and generate proofs for full-node verification. The system supports zero-knowledge and fraud proof.
*Full Node: Run on medium hardware (4-8 cores, 16GB RAM), full node bridges prover, sorter, and EigenDA. They handle compressed state differences through point-to-point networks, apply differences without re-execution of transactions, use proof verification blocks generated by prover, maintain state roots using optimized Merkle Patricia Trie, and support 19x compression synchronization.
(4) Rollup's problem
Monad is fundamentally different from rollup and its inherent trade-offs. Most rollups today rely on a centralized single sorter, although shared and decentralized sorting solutions are being developed. The centralization of the sorter and proposer introduces operational vulnerabilities. Control of a single entity may lead to activity issues and reduced censorship resistance. Despite the existence of an escape pod, a centralized sorter can manipulate transaction speed or sequence to extract MEVs. They also create single point of failure, and if the sorter fails, the entire L2 network will not function properly.
In addition to centralized risks, rollup also brings additional trust assumptions and trade-offs, especially around interoperability:
users encounter multiple non-interchangeable forms of the same asset. The three major rollups—Arbitrum, Optimism, and Base—maintain different ecosystems, use cases and user groups. Users must bridge between rollups to access specific applications, or protocols must be launched on multiple rollups, directing liquidity and users while managing the complexity and security risks associated with bridge integration.
The additional interoperability problem stems from technical limitations (the limited transaction volume per second for the basic L2 layer),This leads to further modularization and pushing execution to L3, especially for gaming. Centralization brings additional challenges.
We have seen optimized rollups (such as Base and MegaETH) improve performance and optimize EVM through centralized sorters, because transactions are sorted and executed without consensus requirements. This allows to reduce block time and increase block size by using a single high-capacity machine, while also creating single point of failure and potential review vectors.
Monad takes a different approach, requiring more powerful hardware than the Ethereum mainnet. While Ethereum L1 validators require 2 core CPUs, 4-8 GB of memory and 25 Mbps bandwidth, the Monad requires 16 core CPUs, 32 GB of memory, 2 TB SSD and 100 Mbps bandwidth. Although Monad's specifications are huge compared to Ethereum, the latter maintains the lowest node requirements to accommodate independent validators, although the hardware recommended by Monad is already accessible today.
In addition to hardware specifications, Monad is redesigning its software stack to achieve larger decentralization than L2s through node distribution. While L2s prioritizes hardware that enhances single sorters, sacrificing decentralization, Monad has modified the software stack while increasing hardware requirements to improve performance while maintaining node distribution.
(5) Monad's EVM's early Ethereum forks mainly modified the consensus mechanism, such as Avalanche, while maintaining the Go Ethereum client for execution. Although there are Ethereum clients in multiple programming languages, they basically replicate the original design. Monad differs by rebuilding consensus and executing components from first principles and zero.
Monad prioritizes maximizing hardware utilization. In contrast, the Ethereum mainnet's emphasis on supporting independent stakeholders limits performance optimization because it needs to be compatible with weaker hardware. This limitation affects improvements in block size, throughput, and block time—ultimately, the speed of the network depends on its slowest validator. Similar to Solana's approach, Monad uses more powerful hardware to increase bandwidth and reduce latency. This strategy leverages all available cores, memory, and SSDs to increase speed. Optimize high-performance device ratios, given the continuous decline in cost of powerful hardwareThe ability to limit low-quality equipment is more practical.
The current Geth client is executed sequentially through single-threading. Blocks contain linearly sorted transactions that convert the previous state to a new state. This status includes all accounts, smart contracts, and stored data. State changes occur when transactions are processed and verified, affecting account balances, smart contracts, token ownership and other data.
Trading is usually run independently. The blockchain state consists of different accounts, each transaction is independently traded, and these transactions usually do not interact with each other. Based on this idea, Monad uses optimistic parallel execution.
Optimistic parallel execution attempts to run transactions in parallel to gain potential performance advantages—the initial assumption will not conflict. Multiple transactions run simultaneously, initially without worrying about their potential conflicts or dependencies. After execution, the system checks whether parallel transactions are actually conflicting with each other and corrects them when there is conflict.
4. Parallel execution of protocol mechanism
(1) Parallel execution of Solana
When users think of parallel execution, they usually think of Solana and SVM, which allows transactions to be executed in parallel through accessing lists. Transactions on Solana include headers, account keys (the instruction address contained in the transaction), block hashs (the hash included when the transaction was created), instructions, and an array of all account signatures required based on the transaction instructions.
Instructions for each transaction include the program address, specify the program to be called; accounts, list all accounts that are read and written by the instruction; and instruction data, specify the instruction handler (function that processes the instruction) and the additional data required by the instruction handler.
Each directive specifies three key details for each account involved:
*The public address of the account
*Does the account require a transaction?
*Does the directive modify the account's data?
Solana uses these specified accountsList identify transaction conflicts in advance. Since all accounts are specified in the instruction, including details of whether they are writable or not, transactions can be processed in parallel if they do not contain any accounts written to the same state.
The process is as follows:
*Solana checks the account list provided in each transaction
*Identifies which accounts will be written
*Checks conflicts between transactions (whether they are written to the same account)
*Tradings with conflicting writes are processed in sequence
*Solana checks the list provided in each transaction
*Selects conflicts between transactions (whether they are written to the same account)
*Tradings with conflicting write operations are processed in sequence
>Solana checks the lists provided in each transaction
*Selana checks the lists provided in each transaction. Users need to pay more in advance because they include this access list in the transaction. The transaction becomes larger and more costly, but users get discounts for specifying access lists.
(2) The parallel execution of Monad is different from Solana, which uses optimistic parallel execution. Unlike identifying which transactions affect which accounts and parallelize based on this (Solana's approach), Monad assumes that transactions can be executed in parallel without interfering with each other.
When Monad runs transactions in parallel, it assumes that the transaction starts at the same point. When multiple transactions run in parallel, the chain generates pending results for each transaction. In this case, the pending result refers to the accounting that the chain makes for tracking the input and output of the transaction and how they affect the state. These pending results are submitted in the original order of the transaction (i.e., based on priority fees).
To submit pending results, check the inputs to make sure they are still valid-if the inputs for pending results have been changed/modified (i.e. if the transactions cannot work in parallel due to accessing the same account and will affect each other, the transactions are processed in order (the transactions will be re-execute later). Re-execution is just to maintain correctness. The result is not that the transaction takes longer, but that it requires more calculations.
In the first execution iteration, Monad has checked for conflicts or dependencies on other transactions. Therefore, when the transaction is executed for the second time (after the first optimistic parallel execution fails), all previous transactions in the block have been executed, ensuring that the second attempt isachievement. Even if all transactions in Monad are interdependent, they are simply executed in order, producing the same results as another non-parallelized EVM.
Monad tracks the read set and write set of each transaction during execution, and then merges the results in the original transaction order. If a transaction running in parallel uses outdated data (because an earlier transaction updated what it reads), Monad detects this when the merge is merged and re-executes the transaction with the correct update status. This ensures that the end result is performed the same as the blocks in sequence, maintaining Ethereum-compatible semantics. This re-execution has minimal overhead – expensive steps such as signature verification or data loading do not need to be repeated from scratch, and the required state is usually cached in memory at the first run.
Example:
In the initial state, user A has 100 USDC, user B has 0 USDC, and user C has 300 USDC. There are three transactions:
*Transaction 1: User A sends 10 USDC to User B
*Transaction 2: User A sends 10 USDC to User C
Serial execution process uses serial execution, the process is simpler, but less efficient. Each transaction is executed in order:
*User A first sends 10 USDC to User B.
*After that user A sends 10 USDC to user C.
In the final state, for serial execution (non-Monad):
*User A has 80 USDC left (10 USDC sent to B and C, respectively).
*User B has 10 USDC.
*User C has 310 USDC.
Execute in parallelProcesses
Use parallel execution, the process is more complex but more efficient. Multiple transactions are processed simultaneously, rather than waiting for each transaction to complete in order. Although transactions run in parallel, the system tracks their input and output. In the sequential "merge" phase, if a transaction is detected to use input changed by an earlier transaction, the transaction will be re-execute with the updated state.
The step-by-step process is as follows:
*User A initially has 100 USDC, User B initially has 0 USDC, and User C initially has 300 USDC.
*By optimistically executed in parallel, multiple transactions run simultaneously, initially assuming that they all start working from the same initial state.
*In this case, transaction 1 and transaction 2 are executed in parallel. Both transactions read User A's initial state is 100 USDC.
*Transaction 1 plans to send USDC 10 from User A to User B, reducing the balance of User A to 90 and increasing the balance of User B to 10.
* At the same time, Transaction 2 also reads the initial balance of User A to 100 and plans to transfer 10 USDC to User C, trying to reduce the balance of User A to 90 and the balance of User C to 310.
* When the chain verifies these transactions in order, first check transaction 1. Since its input value matches the initial state, the submission, User A's balance becomes 90 and User B receives 10 USDC.
*When the chain checks transaction 2, a problem was found: when the transaction 2 plan, it assumes that user A has 100 USDC, but user A now has only 90 USDC. Due to this mismatch, transaction 2 must be re-execute.
* During re-execution, Transaction 2 reads user A's updated status is 90 USDC. Then, 10 USDC was successfully transferred from user A to user C, and user A had 80 USDC left, and the balance of user C increased to USDC 310 USDC.
*In this case, both transactions can be successfully completed because User A has enough funds to make two transfers.
In the final state, for parallel execution (Monad):
The result is the same:
*User A has 80 USDC left (10 USDC sent to B and C, respectively).
*User B has 10 USDC.
*User C has 310 USDC.
*User D has 100 USDC minus NFT cost and minted NFT.
5. Delayed executionWhen blockchain verifies and reaches a transaction consensus, nodes around the world must communicate with each other. This global communication encounters physical limitations because data takes time to transmit between long-distance points such as Tokyo and New York.
Most blockchains use sequential methods, where execution is tightly coupled to consensus. In these systems, execution is a prerequisite for consensus—the node must execute transactions before finalizing the block.
The following are the details:
Execution precedes consensus so that the block is finalized before starting the next block. The node first reaches a consensus on the order of transactions, and then reaches a consensus on Merkelgen, the status summary after the transaction is executed. The leader must execute all transactions in it before sharing the proposed block, and the verification node must execute each transaction before reaching a consensus. This process limits execution time as it occurs twice while allowing multiple rounds of global communication to reach consensus. For example, Ethereum has 12 seconds of blocking time, while actual execution may take only 100 milliseconds (the actual execution time varies greatly depending on block complexity and gas usage).
Some systems try to optimize this by interleaving execution, which divides tasks into smaller segments that alternate between processes. While processing is still sequential and any moment is performed single-task, quick switching creates obvious concurrency. However, this approach still fundamentally limits throughput, as execution and consensus are still interdependent.
Monad solves the limitations of sequential and interleaved execution by decoupling execution from consensus. Nodes reach a consensus on the order of transactions without executing transactions—that is, two parallel processes occur: the node executes a consensus transaction.
*Consensus continues to the next block without waiting for execution to complete, and executes follow the consensus.
This structure enables the system to commit a lot of work through consensus before execution begins, allowing Monad to handle larger blocks and more transactions by allocating additional time. In addition, it enables each process to use the entire block time independently—the consensus can communicate globally using the entire block time, and execution can be calculated using the entire block time, and the two processes do not block each other.
To maintain security and state consistency while decoupling execution from consensus, Monad uses delayed Merkel roots, where each block contains the state Merkel roots before N blocks (N is expected to be 10 at startup and set to 3 in the current testnet), allowing nodes to verify after execution that they have reached the same state. Delayed Merkel root allows chains to verify state consistency: Delayed Merkel root acts as a checkpoint—after N blocks, nodes must prove that they have reached the same state root, otherwise they have performed the wrong content. Furthermore, if the execution of a node produces a different state root, it will detect this after N blocks and can be rolled back and re-execute to reach consensus. This helps eliminate the risk of malicious behavior from nodes. The generated delay Merkel root can be used to light client verification status—although there is a delay of N blocks.
Because execution is delayed and occurs after consensus, a potential problem is that malicious actors (or ordinary users accidentally) constantly submit transactions that will eventually fail due to insufficient funds. For example, if a user with a total balance of 10 MON submitted 5 transactions, each transaction attempting to send 10 MON separately, it could cause problems. However, if no checking is performed, these transactions may pass consensus but fail during execution. To address this issue and reduce potential spam, nodes implement protection measures by tracking on-the-go transactions during consensus.
For each account, the node checks the account balance before N blocks (because this is the latest verified correct state). Then, for each "on-transit" pending transaction for that account (which has been agreed upon but has not been executed yet), they are subtracted from positiveIn the value of the transfer (e.g. sending 1 MON) and the maximum possible gas cost, calculate as gas_limit multiplied by maxFeePerGas.
This process creates a running "available balance" to verify new transactions during consensus. If the value of a new transaction plus the maximum gas cost exceeds this available balance, the transaction is rejected during the consensus period rather than letting it pass after failure during execution.
Because Monad's consensus is conducted in a slightly delayed state view (due to execution decoupling), it implements a protection against containing transactions that the sender cannot ultimately pay. In Monad, each account has an available or "reserve" balance during the consensus period. As the transaction is added to the proposed block, the protocol deducts the maximum possible cost of the transaction (gas * maximum fee + value of the transfer) from that available balance. If the available balance of the account will drop below zero, further transactions for that account will not be included in the block.
This mechanism (sometimes described as charging shipping costs to reserve balances) ensures that only transactions that can be paid are proposed, thus defending against DoS attacks that attackers attempt to flood the network with zero funds. Once the block is finalized and executed, the balance will be adjusted accordingly, but during the consensus phase, the Monad node always conducts the latest check on the spendable balance of pending transactions.
6. MonadBFT
(1) Consensus
HotStuff
MonadBFT is a low-latency, high-throughput Byzantine fault tolerance ("BFT") consensus mechanism, derived from the HotStuff consensus.
Hotstuff was created by VMresearch and further improved by LibraBFT from the former Meta blockchain team. It implements linear view changes and responsiveness, meaning it can effectively rotate the Leaders while doing it at actual network speeds rather than a predetermined timeout. HotStuff also uses threshold signatures for efficiency and implements pipelined operations that allow new blocks to be proposed before the previous block is submitted.
However, these benefits come with certain tradeoffs: extra rounds compared to the classic two-wheeled BFT protocolThe probability of forking during pipeline is higher. Despite these tradeoffs, HotStuff's design makes it more suitable for large-scale blockchain implementations, although it leads to a slower finality than two-wheeled BFT protocols.
The following is a detailed explanation of HotStuff:
*When transactions occur, they are sent to a validator on the network, called the Leader.
*Leader compiles these transactions into a block and broadcasts them to other validators in the network.
*The validator then verifies the block by voting, and the vote is sent to the leader of the next block.
*To prevent malicious actors or communication failures, the block must go through multiple rounds of voting to finalize the status.
*Depending on the specific implementation, blocks can only be submitted after successfully passing two to three rounds, ensuring the robustness and security of the consensus.
While MonadBFT is derived from HotStuff, it introduces unique modifications and new concepts that can be explored further.
Transaction protocol
MonadBFT is specially designed to implement transaction protocols under partial synchronization conditions—meaning that the chain can reach consensus even during asynchronous periods of unpredictable message delays.
End, the network stabilizes and delivers messages (within a known time range). These asynchronous periods originate from Monad's architecture, because the chain must implement certain mechanisms to increase speed, throughput, and parallel execution.
Dual-wheel system
Unlike HotStuff, which initially implemented a three-wheel system, MonadBFT uses a dual-wheel system similar to Jolteon, DiemBFT and Fast HotStuff.
"One round" includes the following basic steps:
*In each round, the Leader broadcasts a new block and a certificate from the previous round (QC or TC).
*Each validator reviews the block and sends a signature vote to the Leader for the next round
*When enough votes are collected (2/3), a QC is formed. QC means that the validators of the network have reached a consensus to attach the block, while TC means that the consensus round fails and needs to be restarted.
"Two-wheel" specifically refers to the submission rules. Submit a block in a dual-wheel system:
*Round 1: The initial block is proposed and QC
*Round 2: The next block is proposed and QC
DiemBFT used a three-wheel system in the past, but was upgraded to a two-wheel system. The two-wheel system achieved faster submissions by reducing communication rounds. It allows for lower latency because transactions can be submitted faster because they do not need to wait for additional confirmation.
Specific process
The consensus process in MonadBFT is as follows:
*Leader operation and block proposal: When the specified leader in the current round starts consensus, the process begins. The leader creates and broadcasts a new block containing user transactions, as well as a proof of the previous round of consensus, in the form of QC or TC. This creates a pipeline structure in which each block proposal carries the authentication of the previous block.
*Verifier action: Once the validator receives the Leader's block proposal, they begin the verification process. Each validator carefully reviews the validity of the block according to the protocol rules. The valid block receives a signature YES vote sent to the next round of the Leader. However, if the validator does not receive a valid block within the expected time, they initiate the timeout procedure by broadcasting a signature timeout message including the highest QC they are known. This dual-path approach ensures that the protocol can make progress even if the block proposal fails.
*Certificate creation: The protocol uses two types of certificates to track consensus progress. When the Leader collects the YES vote from two-thirds of the validators, a QC is created to prove a broad consensus on the block. Or, if two-thirds of the validators time out without receiving a valid proposal, they create a TC, allowing the protocol to safely move to the next round. Both types of certificates serve as key proofs for validator participation.
*Block finalization (two-chain submission rule): MonadBFT uses two-chain submission rule for block finalization. When the validators observe two adjacent authentication blocks from a successive round form a chain B ← QC ← B' ← QC', they can safely submit Block B and all of their ancestors. This two-chain approach provides security and activity while maintaining performance.
Local Memory Pool Architecture
Monad adopts a local memory pool architecture, rather than a traditional global memory pool. In most blockchains, pending transactions are broadcast to all nodes, which can be slow (many network hops) and bandwidth-intensive due to redundant transmissions. In Monad, by contrast, each validator maintains its own memory pool; transactions are forwarded directly by the RPC node to the next few pre-ordered leaders (currently the next N = 3 leaders) for inclusion.
This takes advantage of the known Leader schedule (avoiding unnecessary broadcasting to non-leaders) and ensures that new transactions arrive quickly at block proposals. The upcoming Leader performs verification checks and adds transactions to their local memory pool, so when the validator's turn is on, it already has relevant transaction queues. This design reduces propagation latency and saves bandwidth, achieving higher throughput.
(2) RaptorCast
Monad uses a dedicated multicast protocol called RaptorCast to quickly propagate blocks from the Leader to all validators. Instead of sending the full block serially to each peer or relying on simple broadcasts, the Leader uses an erasure coding scheme (according to RFC 5053) to break down the block proposal data into encoded blocks and efficiently distribute these blocks through a two-level relay tree. In practice, the Leader sends different blocks to a set of first-tier validator nodes, which then forward the blocks to others, so that each validator will eventually receive enough blocks to rebuild the full block. Block allocation is byWeighted (each validator is responsible for forwarding a portion of the block) to ensure load balancing. In this way, the upload capacity of the entire network is used to quickly propagate blocks, minimizing latency, while still tolerating Byzantine (malicious or faulty) nodes that may discard messages. RaptorCast enables Monad to achieve fast and reliable block broadcast even in large blocks, which is critical for high throughput.
BLS and ECDSA signatures
QC and TC are implemented using BLS and ECDSA signatures, which are two different types of digital signature schemes used in cryptography.
Monad uses a combination of BLS signatures and ECDSA signatures for improved security and scalability. BLS signatures support signature aggregation, while ECDSA signatures are usually faster to verify.
ECDSA signature
Although signatures cannot be aggregated, ECDSA signatures are faster. Monad uses them for QC and TC.
QC creation:
*Leader proposes a block
*Verifier agrees by signing voting
*When the required voting parts are collected, they can be combined into a QC.
*QC proves that the verifier agrees to the block
TC creation:
*If the verifier does not receive a valid block within the predetermined time
*It broadcasts a signed timeout message to the peer
*If enough timeout messages are collected, they form a TC.
*TC allows you to enter the next round even if the current round fails
BLS signature Monad uses BLS signatures for multiple signaturesname, because it allows signatures to be gradually aggregated into a single signature. This is mainly used for aggregated message types such as voting and timeouts.
Voting is a message sent by the validator when agreeing to the proposed block. They contain signatures representing the approved block and are used to build QCs.
Timeout is a message sent by the validator when no valid block is received within the expected time. They contain signature messages with the current round number, the highest QC of the validator, and the signature of these values. They are used to build TC.
BLS signature combination/aggregation can be used to save space and improve efficiency. As mentioned earlier, BLS is relatively slower than ECDSA signatures.
Monad uses ECDSA and BLS in combination to benefit from the efficiency of both. Although the BLS scheme is slower, it allows signature aggregation, so it is especially suitable for voting and timeouts, while ECDSA is faster but does not allow aggregation.
7. Monad MEVSimply put, MEV refers to the value that parties can extract by reordering, including or excluding transactions in blocks. MEVs are often classified as “good” MEVs, i.e. MEVs that keep the market healthy and efficient (e.g. liquidation, arbitrage) or “bad” MEVs (e.g. sandwich attacks).
Monad's delayed execution affects how on-chain MEVs work. On Ethereum, execution is a prerequisite for consensus—meaning that when nodes agree on a block, they agree on the transaction list and order and the result state. Before a new block is proposed, the Leader must execute all transactions and calculate the final state, allowing searchers and block builders to reliably simulate transactions for the latest confirmed state.
In contrast, on Monad, consensus and execution are decoupled. The node only needs to agree on the order of transactions in the nearest block, and a consensus on the state may be reached later. This means that validators may work based on the state data of earlier blocks, which makes them unable to simulate against the latest blocks. In addition to the complexity of lack of confirmed state information, Monad's 1-second blocking time can be challenging for builders to simulate blocks to optimize built blocks.
Accessing the latest status data is necessary for searchers because it provides them with confirmation asset prices on DEX, liquidity pool balances, smart contract status, etc. - which enables them toIdentify potential arbitrage opportunities and discover liquidation events. If the latest status data is not confirmed, the searcher cannot simulate the block before the next block is generated and faces the risk of transaction rollback before the status confirmation.
Given the delay in the Monad block, the MEV pattern may be similar to Solana.
As the background, on Solana, blocks are generated in a slot every about 400 milliseconds, but the time between block generation and "rooting" (finalized) is longer - usually 2000-4000 milliseconds. This delay comes not from the block production itself, but from the time it takes to collect enough equity-weighted votes to make the block finalize.
During this voting period, the network continues to process new blocks in parallel. Since transaction fees are very low and new blocks can be processed in parallel, this creates a "race condition" where searchers send a large number of transactions that want to be included - which causes many transactions to be rolled back. For example, 1.3 billion (about 41%) of the 3.16 billion non-voting transactions on Solana were rolled back during December. Jito's Buffalu emphasized as early as 2023 that "98% of arbitrage transactions on Solana failed."
Because of similar block delay effects on Monad, the confirmation status information for the latest block does not exist, and the new block is processed in parallel, the searcher may be incentivized to send a large number of transactions - these transactions may fail because the transactions are rolled back, and the confirmed state is different from the state they are used for simulation.
8. MonadDB
Monad chooses to build a custom database called MonadDB, which is used to store and access blockchain data. A common problem with chain scalability is state growth—that is, the data size exceeds the capacity of the node. Paradigm published a brief research article on state growth in April, highlighting the differences between state growth, historical growth and state access, which they believe are often confused, despite being different concepts that affect the performance of node hardware.
As they pointed out:
*State growth refers to the accumulation of new accounts (account balance and random numbers) and contracts (contract bytecode and storage). The node needs to have enough storage space and memory capacity to adapt to state growth.
*Historical growth refers to the accumulation of new blocks and new transactions. Nodes need to have enough bandwidth to share block data and need to have enough storage space to store block data.
*State access refers to read and write operations used to build and verify blocks.
As mentioned earlier, state growth and historical growth both affect the scalability of the chain, because the data size may exceed the capacity of the node. Nodes need to store data in permanent storage to build, verify, and distribute blocks. In addition, nodes must be cached in memory to synchronize with the chain. State growth and historical growth and optimized state access both need the chain to adapt, otherwise the block size and operations of each block will be limited. The more data in the block, the more read and write operations per block, the greater the historical growth and state growth, and the greater the demand for efficient state access.
While state and historical growth are important factors in scalability, they are not the main problem, especially from a disk performance perspective. MonadDB focuses on managing state growth through logarithmic database scaling. Therefore, increasing state 16 times requires only one more disk access per state read. Regarding historical growth, when the chain has high performance, there will eventually be too much data that cannot be stored locally. Other high-throughput chains, such as Solana, rely on cloud hosting such as Google BigTable to store historical data, which, while effective, sacrifices decentralization due to the dependency of the centralized party. Monad will initially implement a similar solution while ultimately working on a decentralized solution.
(1) Status access
In addition to state growth and historical growth, one of the key implementations of MonadDB is to optimize read and write operations for each block (i.e., improve state access).
Ethereum uses Merkle Patricia Trie ("MPT") to store state. MPT draws on the features of PATRICIA, a data retrieval algorithm, to enable more efficient data retrieval.
Merkle Tree Merkle Tree ("MT") is a set of hash values that are eventually reduced to a single root hash called the Merkle root. The hash value of the data is a fixed-size encrypted representation of the original data. The Merkle root is created by repeatedly hashing the data until a hash value (Merkle root). Usefulness of the Merkle rootThe thing is that it allows validation of leaf nodes (i.e., a single hash value that is repeatedly hashed to create a root) without having to verify each leaf node individually.
This is much more efficient than verifying each transaction alone, especially in large systems where there are many transactions in each block. It creates a verifiable relationship between individual data fragments and allows "Merkle Proof", i.e., by providing the intermediate hash values (log(n) hash values instead of n transactions) required for the transaction and rebuilding the root, it can prove that the transaction is included in the block.
Merkle Patricia Trie
Merkle tree is very suitable for the needs of Bitcoin, where transactions are static, and the main requirement is to prove that transactions exist in the block. However, they are not very suitable for Ethereum's use case, which requires retrieving and updating stored data (e.g., account balances and random numbers, adding new accounts, updating keys in storage), rather than just verifying its existence, which is why Ethereum uses the Merkle Patricia Trie to store state.
Merkle Patricia Trie ("MPT") is a modified Merkle tree used to store and verify key-value pairs in a state database. While MT takes a series of data (such as transactions) and hash them only in pairs, MPT organizes data like a dictionary—each data (value) has a specific address (key) to store. This key-value storage is implemented through Patricia Trie.
Ethereum uses different types of keys to access different types of Tries, depending on the data that needs to be retrieved. Ethereum uses 4 types of Trie:
*World State Trie: Contains the mapping between address and account status.
*Account storage Trie: stores data related to smart contracts.
*Transaction Trie: Contains all transactions contained in the block.
*Receipt Trie: Stores transaction receipts with transaction execution information.
*Trie accesses values through different types of keys, which enables the chain to perform various functions, including checking balances, Verify whether the contract code exists or find specific account data.
Note: Ethereum plans to move from MPT to Verkle tree to "upgrade the Ethereum nodes so that it can stop storing large amounts of state data without losing the ability to verify blocks".
Monad DB: Patricia Trie
Unlike Ethereum, MonadDb implements the Patricia Trie data structure locally on disk and memory.
As mentioned earlier, MPT is a combination of the Merkle tree data structure and Patricia Trie for key-value retrieval: where two different data structures are integrated/combined: Patricia Trie is used to store, retrieve and update key-value pairs, while Merkle tree is used to verify. This results in additional overhead because it adds complexity to hash-based node references and Merkle needs to provide additional storage for hash values on each node.
The data structure based on Patricia Trie enables MonadDB to:
* have a simpler structure: each node has no Merkle hash, and the node relationship has no hash references, it only stores keys and values directly. * Direct path compression: Reduce the number of searches required to arrive at the data. *Local key-value storage: Although MPT integrates Patricia Trie into a separate key-value storage system, the local function of Patricia Trie is key-value storage, which allows for better optimization. *No data structure conversion required: no conversion between Trie format and database format. These make MonadDB relatively low computational overhead, require less storage, enable faster operations (whether it is retrieval or update), and keep a simpler implementation.
Async I/O
Trading is executed in parallel on Monad. This means that the storage needs to adapt to the state of multiple transactions access, i.e. the database should have asynchronous I/O.
MonadDB supports modern asynchronous I/O implementations, which enables it to handle multiple operations without creating a large number of threads—unlike other traditional key-value databases (such as LMDB), the latter must create multiple linesPrograms to handle multiple disk operations—the overhead is less due to fewer threads to manage.
Simple examples of input/output processing in the encryption realm are:
*Input: Read status before transactions to check account balance*Output: Write/update account balance after transfer Asynchronous I/O allows input/output processing (i.e. read and write storage) even if previous I/O operations have not been completed. This is necessary for Monad, as multiple transactions are being executed in parallel. Therefore, one transaction needs to access the storage to read or write the data while another transaction is still reading or writing the data from the storage. In synchronous I/O, the program performs I/O operations one at a time in sequence. When an I/O operation is requested in a synchronous I/O process, the transaction waits until the previous operation is completed. For example:
*Synchronous I/O: Chain writes tx/block #1 to state/store. The chain waits for it to complete. The chain can then be written to tx/block #2. *Async I/O: The chain writes tx/block #1, tx/block #2 and tx/block #3 to state/store at the same time. They are done independently.
(2) StateSync
Monad has a StateSync mechanism to help new or lagging nodes catch up with the latest state efficiently without replaying every transaction from creation. StateSync allows a node ("client") to request a snapshot of the most recent state from its peer ("server") to the target block. The status data is divided into blocks (such as part of the account state and the nearest block header) that are distributed among multiple validator peers to share the load. Each server responds to the requested state block (with metadata in MonadDb quickly retrieves the required Trie nodes), and the client assembles these blocks to build the state of the target block. As the chain continues to grow, once the synchronization is complete, the node either performs another round of StateSync closer to the top or replays a small number of nearest blocks to catch up completely. This chunked state synchronization greatly accelerates node boot and recovery, ensuring that even if Monad's state grows, new validators can join or restart and fully synchronize without hours of delay.
9. Ecosystem(1) Ecosystem efforts
The Monad team focuses on developing a strong and robust ecosystem for its chain. The past few years, The competition between L1 and L2 has shifted from focusing primarily on performance to user-oriented applications and developer tools. Chains are not enough to just brag about high TPS, low latency and low fees; they now have to provide an ecosystem of a wide variety of applications, from DePIN to AI, from DeFi to consumers. This is becoming increasingly important because of the surge in high-performance and low-cost L1s, including Solana, Sui, Aptos and Hyperliquid, which all offer high-performance, low-cost development environments and block space. One advantage of Monad here is that it uses EVM. As mentioned earlier, Monad provides complete EVM bytecode and Ethereum RPC API compatibility, enabling developers and users to integrate without changing their existing workflows. One often criticism for those who work to scale EVM is that there are more efficient alternatives available, such as SVM and MoveVM. However, if a team can maximize EVM performance with software and hardware improvements while keeping fees low, it makes sense to scale EVM because there are existing network effects, developer tools and a capital base that can be easily accessed.
Monad's full EVM bytecode compatibility enables applications and protocol instances to be ported from other standard EVMs such as ETH mainnet, Arbitrum, and OP Stack without changing the code. This compatibility has both advantages and disadvantages. The main advantage is that existing teams can easily port their applications to Monad. In addition, developers creating new applications for Monad can leverage the rich resources, infrastructure and tools developed for EVMs such as wallets such as Hardhat, Apeworx, Foundry, Rabby and Phantom, as well as analysis and indexing products such as Etherscan, Parsec and Dune.
One of the disadvantages of easy-to-port protocols and applications is that they can lead to lazy, inefficient forks and applications starting on-chain. While it is important for a chain to have many products available, most should be unique applications that are not accessible on other chains. For example, while most chains require Uniswap V2 style or AMM based on centralized liquidity, chains must also attract a new class of protocols and applications to attract users. Existing EVM tools and developer resources help to enable novel and unique applications. Additionally, the Monad team implemented various programs, from accelerators to venture capital competitions to encourage novel protocols and applications on the chain.
(2) Ecosystem Overview
Before diving into the specific categories that are suitable for Monad, it may be helpful to understand why applications choose to start on L1 rather than launch on L2 or launch their own L1/L2/application chain.
On the one hand, starting your own L1, L2 or application chain can be beneficial because you don't have to face noisy neighbor problems. Your block space is entirely owned by you, so you can avoid congestion during high activity and maintain consistent performance regardless of overall network load. This is especially important for CLOBs and consumer applications. During congestion, traders may not be able to execute transactions, and everyday users who expect Web2 performance may find that the application is not available due to slower speeds and performance degradation.
On the other hand, launching your own L1 or application chain requires guiding a group of validators, and more importantly, incentivizing users to bridge liquidity and capital to use your chain. While Hyperliquid successfully launched its own L1 and attracted users, there are many teams who failed to do this. Building on the chain allows teams to benefit from network effects, provide secondary and tertiary liquidity effects, and enable them to integrate with other DeFi protocols and applications. It also eliminates the need to focus on infrastructure and build stacks – which is difficult to do efficiently and efficiently. It should be noted that building an application or protocol is very different from building an L1 or an application chain.
Starting your own L2 can relieve some of this stress, especially the technical issues related to booting the validator set and building infrastructure, as there are click-to-deploy rollup-as-a-service providers. However, these L2s are generally not particularly efficient (most still do not have TPS supporting consumer applications or CLOBs) and tend to have risks associated with centralization (most are still in phase 0). Furthermore, they still face disadvantages associated with liquidity and activity fragmentation, such as low activity and user-per-second operation (UOPS).
*CLOB
The order book on the complete chain has beenBecome the benchmark for the DEX industry. While this was previously impossible due to network-level limitations and bottlenecks, the recent surge in high throughput and low-cost environments means on-chain CLOBs are now possible. Previously, high gas fees (making orders on-chain expensive), network congestion (due to necessary transaction volumes) and latency issues made transactions based entirely on-chain order books unrealistic. Furthermore, the algorithms used in the CLOB matching engine consume a lot of computing resources, making it challenging and costly to implement them on-chain.
The model based entirely on-chain order book combines the advantages of traditional order book and the complete transparency of transaction execution and matching. All orders, transactions and matching engines themselves exist on the blockchain, ensuring full visibility at every level of the transaction process. This approach offers several key advantages. First, it provides complete transparency, as all transactions are recorded on the chain, not just transaction settlement, allowing for full auditability.
Secondly, it mitigates MEV by reducing the chance of preemptive transactions at the order placement and cancellation levels, making the system more fair and resistant to manipulation.
Finally, it eliminates the trust assumption and reduces the risk of manipulation, as the entire order book and matching process exist on the chain, eliminating the need for trust for off-chain operators or insiders in the protocol, and making it more difficult for either party to manipulate order matching or execution. In contrast, the off-chain order book compromises in these respects, which may allow insiders to preempt transactions and order book operator manipulation due to the lack of complete transparency in the order placement and matching process.
On-chain order books have advantages over off-chain order books, but they also have significant advantages over AMMs:
Although AMMs usually suffer price slippage due to LVR and IL, and are susceptible to arbitrage utilization of outdated prices, on-chain order books eliminate liquidity provider exposure to IL or LVR by liquidity providers. In fact, time order matching prevents outdated pricing and reduces arbitrage opportunities through efficient price discovery. However, AMMs do have advantages over risky and low liquidity assets, as they enable license-free trading and asset listings, enabling price discovery for new and poorly liquid tokens. It should be noted that, as mentioned earlier, LVR is less problematic compared to some alternatives given the short block time on Monad.
Projects worth paying attention to include: Kuru, Yamata, Composite Labs, etc.
*DePIN
Blockchains are essentially ideal for processing payments because they have a global shared state that is resistant to censorship and fast transaction and settlement times. However, to efficiently support payments and value transfers, the chain needs to provide low and predictable fees and fast finality. As a high-throughput L1, Monad can support emerging use cases such as DePIN applications that not only require high payment volumes but also require on-chain transactions to effectively verify and manage hardware.
Historically, we have seen most DePIN applications launch on Solana for many reasons. The localized fee market allows Solana to provide low-cost transactions when other parts of the chain are congested. More importantly, Solana has successfully attracted many DePIN applications because there are many existing DePIN applications on the network. Historically, the DePIN application has not been launched on Ethereum because of slow settlement speed and high fees. As DePIN becomes increasingly popular, Solana has emerged as a competitor of low-cost and high throughput over the past few years— resulting in DePIN applications choosing to launch there. As more and more DePIN applications choose to launch on Solana, a relatively large community of DePIN developers and applications, as well as toolkits and frameworks are formed. This leads to more DePIN applications being selected to launch where there are already technology and development resources.
However, as an EVM-based high-throughput low-cost competitor, Monad has the opportunity to attract DePIN's attention and applications. To this end, it will be crucial to develop frameworks, toolkits and ecosystem programs to attract existing and new DePIN applications. While DePIN applications can try to build their own networks (whether as L2 or L1), Monad provides a high-throughput underlying layer that enables network effects, composability with other applications, deep liquidity and powerful developer tools.
Projects worth paying attention to are: SkyTrade
*Social and consumer applications
Although financial applications have dominated the field of encryption in the past few years, consumers and social applications have received more and more attention in the past year. These applications provide alternative monetization pathways for creators and those who wish to leverage their social capital. They are also designed to provide censorship resistance,Combined and increasingly financialized versions of social graphs and experiences allow users to have better control over their data—or at least gain more from it. Similar to the DePIN use case, social and consumer applications require a chain that can efficiently support payments and value transfers—and therefore require the base layer to provide low and predictable fees and fast finality. The most important thing here is delay and finality. Since the Web 2 experience is now highly optimized, most users expect similar low-latency experiences. The slow experience of payment, shopping and social interaction can frustrate most users. Given that decentralized social media and consumer applications have generally lost to existing centralized social media and consumer applications, they need to provide an equal or better experience to attract users and attention.
Monad's fast finality architecture is ideal for providing users with low latency and low cost experiences.
Projects worth paying attention to are: Kizzy, Dusted
In addition to CLOB, DePIN and consumer/social applications built on Monad, we are also excited about the next generation of basic applications, such as aggregators and LSDs and AI products.
General-purpose chains need to have a wide range of basic products to attract and retain users—so that users do not need to jump from one link to another to meet their needs. That's the case with L2 so far. As mentioned earlier, users may need to meet their options trading or perpetual contract needs on Arbitrum, while also needing to bridge to Base for social and consumer applications, and then to Sanko or Xai for gaming. The success of a general-purpose chain depends on providing all these capabilities in a unified state, with low cost, low latency, high throughput and high speed.
The following are some selected applications to highlight ecosystem projects built on Monad:
*The projects worth paying attention to in mobile staking applications are: Stonad, AtlasEVM, Kintsu, aPriori, Magma, etc.
*AI application
Projects worth paying attention to are: Playback, Score, Fortytwo, Monorail, Mace, etc.